AWK的工作模式 awk 'Pattern {Action}' 其中 Pattern
常用变量及函数 #
熟记的变量 #
NF
#
NF 最后一个域,$NF获取最后一个域的值。如下
echo {a..d} | awk '{print NF, $NF}'4 d
NR/FNR
#
NR表示awk开始执行程序后所读取的数据行数。FNR与NR功用类似,不同的是awk每打开一个新文件,FNR便从0重新累计。如果是一个文件的话,NF和FNR没有区别
有两个文件格式如下:
account文件
张三|000001
李四|000002
cdr文件
000001|10
000001|20
000002|30
000002|15
想要得到的结果如下
张三|000001|10
张三|000001|20
李四|000002|30
李四|000002|15
FS/OFS
#
FS输入字段分隔符,默认为空格。OFS输出字段分隔符,默认为空格。
echo "1:2:3" | awk 'BEGIN{FS=":"; OFS=","} {print $1, $2, $3}'1,2,3
RS/ORS/RT
#
RS输入记录分隔符,默认为换行符。ORS输出记录的分隔符默认为换行符号。
➜ cat file
a b:c d
e f:g h
下面这命令解释,首先修改了RS的,则上面的file文件中的行会变成下面三行内容。然后后面打印第2列,即输出的结果为b d h
a b
c d e f
g h
➜ cat file | awk 'BEGIN{RS=":"} {print $2}'
b
d
h
➜ cat file | awk 'BEGIN{RS=":"; ORS=","} {print $2}'
b,d,h,
➜ cat file | awk 'BEGIN{RS=":"; ORS=","} {print $2, "<"RT">"}'
b <:>,d <:>,h <>,
如上面的一个例子 RT的值就是匹配到的RS的值,RS的值可以采用正则进行设定。
了解的变量 #
ARGC
#
ARGV
#
FILENAME
#
ARGIND
#
熟记的函数 #
sub
#
gsub
#
substr
#
split
#
length
#
getline
#
system
#
了解的函数 #
gensub
#
index
#
match
#
tolower
#
toupper
#
close
#
不常用变量 #
OFMT 格式化数字
#
awk 'BEGIN{OFMT="%.4f"; print 3.1415926}'3.1416
FIELDWIDTHS 设置字段固定宽度
#
下面的例子意思把字符串 “123456"分为3段,第一段为2个宽度,第二段为一个宽度,第三段为3个宽度。
echo "123456" | awk 'BEGIN{FIELDWIDTHS="2 1 3"} {print $2}'3
IGNORECASE 忽略大小写
#
echo 'HELLO world' | awk '{IGNORECASE=1}/hello/{print}'HELLO world
RSTART match()匹配的第一个字符的索引
#
如果没匹配 RSTART=0
echo 'HELLO world' | awk '{IGNORECASE=1; m=match($0, /[a-z]+$/); print m, RSTART, RLENGTH}'7 7 5
RLENGTH match()匹配的字符串长度
#
如果没有匹配成功 RLENGTH=-1
echo 'HELLO world' | awk '{IGNORECASE=1; m=match($0, /^[a-z]+$/); print m, RSTART, RLENGTH}'0 0 -1
echo 'HELLO world' | awk '{IGNORECASE=1; m=match($0, /^[a-z ]+$/); print m, RSTART, RLENGTH}'1 1 11
数组简单应用 #
a xxx
b yyy
c ggg
a bbb
b ddd
d ccc
删除第一列重复的行 #
sort | uniq -w 2awk '!array[$1]++'awk的一个特性,如果没有action即引号中的值如果非零值打印。sed -n 'G; s/\n/&&/; /^\(.\).*\n.*\n\1/d; s/\n//; h; P'
a xxx
b yyy
c ggg
d ccc
统计第一列出现的次数和百分比 #
- 把所有需要统计的数据放到数组中
- NR 为处理的总行数
- END 最后统一处理输出
➜ awk '{a[$1]++;} END { for(i in a) print i, a[i], a[i]*100/NR"%" }' a
a 2 33.3333%
b 2 33.3333%
c 1 16.6667%
d 1 16.6667%
- 如果需要保持下标顺序的话可以使用
asorti函数
awk '{a[$1]++;l=asorti(a,b)}END{for(i=1;i<=l;i++)print b[i],a[b[i]],a[b[i]]*100/NR"%"}' a
强大的getline
#
| Variant | Effect |
|---|---|
| getline | Sets $0, NF, FNR, and NR |
| getline var | Sets var, FNR, and NR |
| getline < file | Sets $0, NF |
| getline var < file | Sets var |
| command | getline |
| command | getline var |
| command | & getline |
| command | & getline var |
下面示例操作的文件原始内容如下
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
awk 'BEGIN{OFS="---"} {getline; print $0, NR, NF} ' file
awk进来的时候getline没有输入获取到下一行内容,重新设置$0。即可以把getline的命令理解为操作下一行的内容。读取到最后一行的时候 getline 读取下一行会失败,后面的处理命令处理的为当前行。
➜ awk 'BEGIN{OFS="---"} {getline; print $0, NR, NF} ' file
2 3---2---2
7 8 9 10---4---4
11 12 13 14 15---5---5
awk 'BEGIN{OFS="---"} {getline var; print $0, NR, NF} ' file
getline赋值给个变量,$0不会变化。
➜ awk 'BEGIN{OFS="---"} {getline var; print $0, NR, NF} ' file
1---2---1
4 5 6---4---3
11 12 13 14 15---5---5
getline实际应用
#
输出文本偶数行 #
awk '{getline}1'1 这里默认等于print $0awk '!(NR%2)' fileawk 'i++%2' fileawk '{if (NR%2==1) next } 1' filesed -n 'n;p' file
输出文本奇数行 #
awk 'NR%2' fileawk '{getline var; print $0}' file
getline容易忽视的close
#
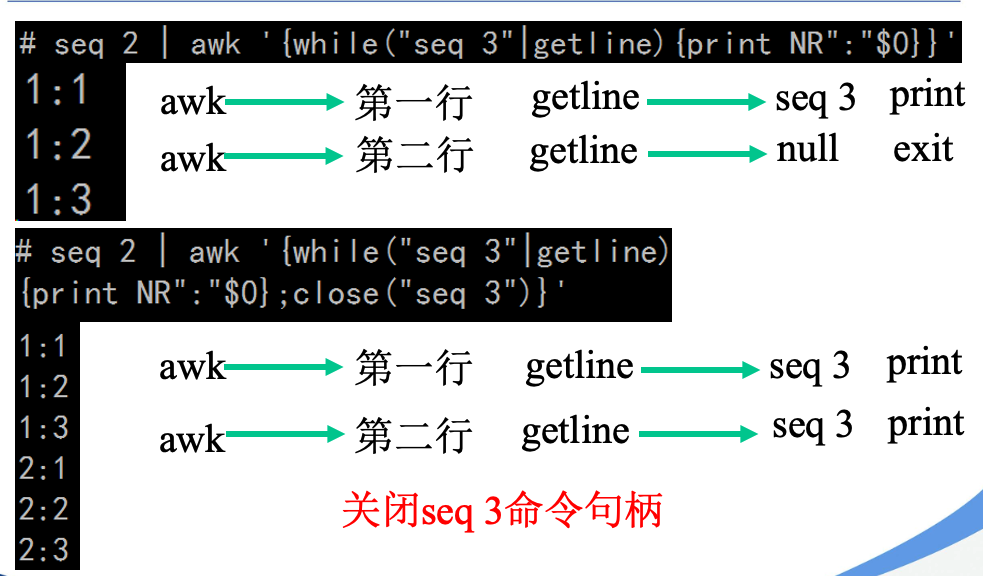
seq 2 | awk '{while("seq 3"|getline){print NR ":" $0} }'
1:1
1:2
1:3
seq 2 | awk '{while("seq 3"|getline){print NR ":" $0}; close("seq 3") }'
1:1
1:2
1:3
2:1
2:2
2:3
FS/RS应用举例 #
cache usage of id:2500 is 90.0%
cache usage of id:2510 is 91.8%
cache usage of id:2520 is 91.6%
cache usage of id:2530 is 21.0%
cache usage of id:2540 is 93.7%
cache usage of id:2550 is 61.4%
cache usage of id:2560 is 63.8%
cache usage of id:2570 is 72.6%
cache usage of id:2580 is 91.0%
cache usage of id:2590 is 64.1%
TotalMemory:16243 TotalCache:12000 ServCacheUsage:%74.09
目标输出大于90%的id,按照如下格式进行输出
id2510:91.8% id2520:91.6% id2540:93.7% id2580:91.0%
思路
awk -F'[ %]' 'BEGIN{OFS=":"; ORS="\t"}/^cache usage/{if($(NF-1)>90){split($4, array,":"); print "id"array[2], $(NF-1)"%"}}' cache
遍历数据的方式
awk -F'[ %]' 'BEGIN{OFS=":"; ORS="\t"}/^cache usage/{a[$4]=$(NF-1)} END{for(i in a){if(a[i]>90) print i, a[i]}}' cache
FS/RS 陷阱 #
# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 52:54:00:6c:ff:1b brd ff:ff:ff:ff:ff:ff
inet 9.148.210.6/24 brd 9.148.210.255 scope global eth1
valid_lft forever preferred_lft forever
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 20:90:6f:30:f0:79 brd ff:ff:ff:ff:ff:ff
上述文件显示 ip addr的输出,为了方便分析网卡的信息,如何将网卡所有信息合并为一行。
陷阱需要设置 $1=$1;或者引入变量的时候不要使用 -v,把模式匹配放到begin中。
ip addr | head -n 10 | awk -v RS=": eth" '/eth/{$1=$1; print "eth"$0}'
eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 52:54:00:6c:ff:1b brd ff:ff:ff:ff:ff:ff inet 9.148.210.6/24 brd 9.148.210.255 scope global eth1 valid_lft forever preferred_lft forever 3
eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 20:90:6f:30:f0:79 brd ff:ff:ff:ff:ff:ff
echo "1:2:3:4" | awk '{FS=":"; print $1}'FS设置的没有生效1:2:3:4
echo "1:2:3:4" | awk 'BEGIN{FS=":"} {print $1}'1
echo "1:2:3:4" | awk '{FS=":"; $0=$0; print $1}'1
echo "1 2 3 4" | awk 'BEGIN{OFS=":"} {print $1, $2, $3, $4}'1:2:3:4
echo "1 2 3 4" | awk 'BEGIN{OFS=":"} {print $0}'1 2 3 4
echo "1 2 3 4" | awk 'BEGIN{OFS=":"} {$1=$1; print $0}'1:2:3:4
对多行文本的分析技巧 NR / FNR #
- 将两个文本 x, y 洗哪个相同字段相加,并输出如下。
1 2 6 5 7 7
3 4 + 4 3 = 7 7
5 6 2 1 7 7
NR==FNR 时在处理第一个文件
awk 'NR==FNR{a[NR]=$1; b[NR]=$2} NR>FNR{print $1+a[FNR], $2+b[FNR]}' x yawk 'ARGIND==1{a[NR]=$1;b[NR]=$2}ARGIND==2{print $1+a[FNR],$2+b[FNR]}' x yawk 'FILENAME=="x"{a[NR]=$1;b[NR]=$2}FILENAME=="y"{print $1+a[FNR],$2+b[FNR]}' x yawk '{print $1 + $3" "$2 + $4}' <(paste x y)
通过实例掌握技巧 #
将第二次出现的1替换为 @
#
➜ Desktop cat aaa
1
3
1
2
➜ Desktop awk '/1/{a++;if(2==a)gsub(/1/, "@", $0)}1' aaa
1
3
@
2
将偶数行附加在奇数行后 #
- `seq 4 | awk ‘{printf $0” “, getline; print $0}’-
➜ Desktop seq 4 | awk '{printf $0" ", getline; print $0}'
1 2
3 4
seq 4 | awk '{a=$0; getline; print a, $0}'
➜ Desktop seq 4 | awk '{a=$0; getline; print a, $0}'
1 2
3 4
awk '{if(NR%2==0)print a,$0; a=$0}'
➜ Desktop seq 4 | awk '{if(NR%2==0)print a,$0; a=$0}'
1 2
3 4
seq 4 | sed 'N;s/\n/ /'
➜ Desktop seq 4 | sed 'N;s/\n/ /'
1 2
3 4
输出指定行前n行内容
#
awk '{a[NR]=$0}/\<1000\>/{for(i=NR-5;i<NR;i++)print a[i];exit}' <(seq 5000)- 输出1000的前5行
awk '{a[NR%5]=$0-1}/\<1000\>/{for(i=NR-5;i<NR;i++)print a[i%5];exit}' <(seq 5000)awk '/\<1000\>/{for(i=NR-5;i<NR;i++)print a[i%5];exit} {a[NR%5]=$0}' <(seq 5000)
二位数组的使用 #
已知文件内容如下
SERVERCOUNT 9
SERVERRANGE 0-2,3-5,6-9,10-12,13-15,16-19,20-22,23-25,26-29
CACHESIZE 1200,1200,1500,1200,1200,1500,1200,1200,1500
想要输出的文件内容如下
SERVERRANGE CACHESIZE
0-2 1200
3-5 1200
6-9 1500
10-12 1200
13-15 1200
16-19 1500
20-22 1200
23-25 1200
26-29 1500
脚本
#!/bin/bash
FILENAME=$1
cat $FILENAME | egrep 'SERVERRANGE|CACHESIZE' | \
sed 's/,/ /g' | \
gawk '{
for(i=1;i<=NF;i++)
a[NR"-"i]=$i
if(NF>tag)tag=NF
}
END {
for(i=1;i<=tag;i++) {
for(j=1;j<=NR;j++) {
if(!a[j"-"i])
printf("null")
printf("%s ", a[j"-"i])
}
printf("\n")
}
}'
输出每个模块中的最大值 #
思路: 每个module为下标,取值大的数字为该下标的值
#!/bin/bash
TMPFILE=/tmp/test
cat > $TMPFILE <<EOF
MODULE1
1.5
2.5
3.5
MODULE2
4.5
6.5
5.5
EOF
cat $TMPFILE | gawk '
/MODULE/{
a=$0
}
m[a]<$0 && $0!=a {
m[a]=$0
}
END {
for(a in m)
print a, m[a]
}'
或使用 next
cat $TMPFILE | gawk '
/MODULE/{
a=$0;
next
}
m[a]<$0 { m[a]=$0 }
END {
for(a in m)
print a, m[a]
}'
统计每个模块中的行数 #
#!/bin/bash
TMPFILE=/tmp/test
cat > $TMPFILE <<EOF
AAA
01234,12343,1231 3fdja,fasd
23231,3231,1233
323213,313,13
323,323,112,12,1,2
312,233
BБB
323,
12,1
43,3
CCC
344,2, 2
4,2,1
23,4
EOF
cat $TMPFILE | gawk '
BEGIN {
FS=","
}
{
if(NF==1) {
if(NR>1)
print m" --- "i,n
m=$0
n=""
i=0
} else {
n=n"\n"$0
i++
}
}
END{
print m" --- "i,n
}'
输出结果
AAA --- 5
01234,12343,1231 3fdja,fasd
23231,3231,1233
323213,313,13
323,323,112,12,1,2
312,233
BБB --- 3
323,
12,1
43,3
CCC --- 3
344,2, 2
4,2,1
23,4