本文由 简悦 SimpRead 转码, 原文地址 mp.weixin.qq.com
刚开始写这篇文章的时候,目标非常大,想要探索 Go 程序的一生:编码、编译、汇编、链接、运行、退出。它的每一步具体如何进行,力图弄清 Go 程序的这一生。
在这个过程中,我又复习了一遍《程序员的自我修养》。这是一本讲编译、链接的书,非常详细,值得一看!数年前,我第一次看到这本书的书名,就非常喜欢。因为它模仿了周星驰喜剧之王里出现的一本书 ——《演员的自我修养》。心向往之!
在开始本文之前,先推荐一位头条大佬的博客——《面向信仰编程》,他的 Go 编译系列文章,非常有深度,直接深入编译器源代码,我是看了很多遍了。博客链接可以从参考资料里获取。
理想很大,实现的难度也是非常大。为了避免砸了 “深度解密” 这个牌子,这次起了个更温和的名字,嘿嘿。
下面是文章的目录:
引入
我们从一个 HelloWorld 的例子开始:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
当我用我那价值 1800 元的 cherry 键盘潇洒地敲完上面的 hello world 代码时,保存在硬盘上的 hello.go 文件就是一个字节序列了,每个字节代表一个字符。
用 vim 打开 hello.go 文件,在命令行模式下,输入命令:
:%!xxd
就能在 vim 里以十六进制查看文件内容:
最左边的一列代表地址值,中间一列代表文本对应的 ASCII 字符,最右边的列就是我们的代码。再在终端里执行 man ascii:
和 ASCII 字符表一对比,就能发现,中间的列和最右边的列是一一对应的。也就是说,刚刚写完的 hello.go 文件都是由 ASCII 字符表示的,它被称为 文本文件,其他文件被称为 二进制文件。
当然,更深入地看,计算机中的所有数据,像磁盘文件、网络中的数据其实都是一串比特位组成,取决于如何看待它。在不同的情景下,一个相同的字节序列可能表示成一个整数、浮点数、字符串或者是机器指令。
而像 hello.go 这个文件,8 个 bit,也就是一个字节看成一个单位(假定源程序的字符都是 ASCII 码),最终解释成人类能读懂的 Go 源码。
Go 程序并不能直接运行,每条 Go 语句必须转化为一系列的低级机器语言指令,将这些指令打包到一起,并以二进制磁盘文件的形式存储起来,也就是可执行目标文件。
从源文件到可执行目标文件的转化过程:
完成以上各个阶段的就是 Go 编译系统。你肯定知道大名鼎鼎的 GCC(GNU Compile Collection),中文名为 GNU 编译器套装,它支持像 C,C++,Java,Python,Objective-C,Ada,Fortran,Pascal,能够为很多不同的机器生成机器码。
可执行目标文件可以直接在机器上执行。一般而言,先执行一些初始化的工作;找到 main 函数的入口,执行用户写的代码;执行完成后,main 函数退出;再执行一些收尾的工作,整个过程完毕。
在接下来的文章里,我们将探索 编译和 运行的过程。
编译链接概述
Go 源码里的编译器源码位于 src/cmd/compile 路径下,链接器源码位于 src/cmd/link 路径下。
编译过程
我比较喜欢用 IDE(集成开发环境)来写代码, Go 源码用的 Goland,有时候直接点击 IDE 菜单栏里的 “运行” 按钮,程序就跑起来了。这实际上隐含了编译和链接的过程,我们通常将编译和链接合并到一起的过程称为构建(Build)。
编译过程就是对源文件进行词法分析、语法分析、语义分析、优化,最后生成汇编代码文件,以 .s 作为文件后缀。
之后,汇编器会将汇编代码转变成机器可以执行的指令。由于每一条汇编语句几乎都与一条机器指令相对应,所以只是一个简单的一一对应,比较简单,没有语法、语义分析,也没有优化这些步骤。
编译器是将高级语言翻译成机器语言的一个工具,编译过程一般分为 6 步:扫描、语法分析、语义分析、源代码优化、代码生成、目标代码优化。下图来自《程序员的自我修养》:
词法分析
通过前面的例子,我们知道,Go 程序文件在机器看来不过是一堆二进制位。我们能读懂,是因为 Goland 按照 ASCII 码(实际上是 UTF-8)把这堆二进制位进行了编码。例如,把 8 个 bit 位分成一组,对应一个字符,通过对照 ASCII 码表就可以查出来。
当把所有的二进制位都对应成了 ASCII 码字符后,我们就能看到有意义的字符串。它可能是关键字,例如:package;可能是字符串,例如:“Hello World”。
词法分析其实干的就是这个。输入是原始的 Go 程序文件,在词法分析器看来,就是一堆二进制位,根本不知道是什么东西,经过它的分析后,变成有意义的记号。简单来说,词法分析是计算机科学中将字符序列转换为标记(token)序列的过程。
我们来看一下维基百科上给出的定义:
词法分析(lexical analysis)是计算机科学中将字符序列转换为标记(token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称 lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
.go 文件被输入到扫描器(Scanner),它使用一种类似于 有限状态机的算法,将源代码的字符系列分割成一系列的记号(Token)。
记号一般分为这几类:关键字、标识符、字面量(包含数字、字符串)、特殊符号(如加号、等号)。
例如,对于如下的代码:
slice[i] = i * (2 + 6)
总共包含 16 个非空字符,经过扫描后,
| 记号 | 类型 |
|---|---|
| slice | 标识符 |
| [ | 左方括号 |
| i | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| i | 标识符 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
上面的例子源自《程序员的自我修养》,主要讲解编译、链接相关的内容,很精彩,推荐研读。
Go 语言(本文的 Go 版本是 1.9.2)扫描器支持的 Token 在源码中的路径:
src/cmd/compile/internal/syntax/token.go
感受一下:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
还是比较熟悉的,包括名称和字面量、操作符、分隔符和关键字。
而扫描器的路径是:
src/cmd/compile/internal/syntax/scanner.go
其中最关键的函数就是 next 函数,它不断地读取下一个字符(不是下一个字节,因为 Go 语言支持 Unicode 编码,并不是像我们前面举得 ASCII 码的例子,一个字符只有一个字节),直到这些字符可以构成一个 Token。
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}
代码的主要逻辑就是通过 c:=s.getr() 获取下一个未被解析的字符,并且会跳过之后的空格、回车、换行、tab 字符,然后进入一个大的 switch-case 语句,匹配各种不同的情形,最终可以解析出一个 Token,并且把相关的行、列数字记录下来,这样就完成一次解析过程。
当前包中的词法分析器 scanner 也只是为上层提供了 next 方法,词法解析的过程都是惰性的,只有在上层的解析器需要时才会调用 next 获取最新的 Token。
语法分析
上一步生成的 Token 序列,需要经过进一步处理,生成一棵以 表达式为结点的 语法树。
比如最开始的那个例子, slice[i]=i*(2+6),得到的一棵语法树如下:
整个语句被看作是一个赋值表达式,左子树是一个数组表达式,右子树是一个乘法表达式;数组表达式由 2 个符号表达式组成;乘号表达式则是由一个符号表达式和一个加号表达式组成;加号表达式则是由两个数字组成。符号和数字是最小的表达式,它们不能再被分解,通常作为树的叶子节点。
语法分析的过程可以检测一些形式上的错误,例如:括号是否缺少一半, + 号表达式缺少一个操作数等。
语法分析是根据某种特定的形式文法(Grammar)对 Token 序列构成的输入文本进行分析并确定其语法结构的一种过程。
语义分析
语法分析完成后,我们并不知道语句的具体意义是什么。像上面的 * 号的两棵子树如果是两个指针,这是不合法的,但语法分析检测不出来,语义分析就是干这个事。
编译期所能检查的是静态语义,可以认为这是在 “代码” 阶段,包括变量类型的匹配、转换等。例如,将一个浮点值赋给一个指针变量的时候,明显的类型不匹配,就会报编译错误。而对于运行期间才会出现的错误:不小心除了一个 0 ,语义分析是没办法检测的。
语义分析阶段完成之后,会在每个节点上标注上类型:
Go 语言编译器在这一阶段检查常量、类型、函数声明以及变量赋值语句的类型,然后检查哈希中键的类型。实现类型检查的函数通常都是几千行的巨型 switch/case 语句。
类型检查是 Go 语言编译的第二个阶段,在词法和语法分析之后我们得到了每个文件对应的抽象语法树,随后的类型检查会遍历抽象语法树中的节点,对每个节点的类型进行检验,找出其中存在的语法错误。
在这个过程中也可能会对抽象语法树进行改写,这不仅能够去除一些不会被执行的代码对编译进行优化提高执行效率,而且也会修改 make、new 等关键字对应节点的操作类型。
例如比较常用的 make 关键字,用它可以创建各种类型,如 slice,map,channel 等等。到这一步的时候,对于 make 关键字,也就是 OMAKE 节点,会先检查它的参数类型,根据类型的不同,进入相应的分支。如果参数类型是 slice,就会进入 TSLICE case 分支,检查 len 和 cap 是否满足要求,如 len <= cap。最后节点类型会从 OMAKE 改成 OMAKESLICE。
中间代码生成
我们知道,编译过程一般可以分为前端和后端,前端生成和平台无关的中间代码,后端会针对不同的平台,生成不同的机器码。
前面词法分析、语法分析、语义分析等都属于编译器前端,之后的阶段属于编译器后端。
编译过程有很多优化的环节,在这个环节是指源代码级别的优化。它将语法树转换成中间代码,它是语法树的顺序表示。
中间代码一般和目标机器以及运行时环境无关,它有几种常见的形式:三地址码、P - 代码。例如,最基本的 三地址码是这样的:
x = y op z
表示变量 y 和 变量 z 进行 op 操作后,赋值给 x。op 可以是数学运算,例如加减乘除。
前面我们举的例子可以写成如下的形式:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2
这里 2 + 6 是可以直接计算出来的,这样就把 t1 这个临时变量 “优化” 掉了,而且 t1 变量可以重复利用,因此 t2 也可以 “优化” 掉。优化之后:
t1 = i * 8
slice[i] = t1
Go 语言的中间代码表示形式为 SSA(Static Single-Assignment,静态单赋值),之所以称之为单赋值,是因为每个名字在 SSA 中仅被赋值一次。。
这一阶段会根据 CPU 的架构设置相应的用于生成中间代码的变量,例如编译器使用的指针和寄存器的大小、可用寄存器列表等。中间代码生成和机器码生成这两部分会共享相同的设置。
在生成中间代码之前,会对抽象语法树中节点的一些元素进行替换。这里引用《面向信仰编程》编译原理相关博客里的一张图:
例如对于 map 的操作 m[i],在这里会被转换成 mapacess 或 mapassign。
Go 语言的主程序在执行时会调用 runtime 中的函数,也就是说关键字和内置函数的功能其实是由语言的编译器和运行时共同完成的。
中间代码的生成过程其实就是从 AST 抽象语法树到 SSA 中间代码的转换过程,在这期间会对语法树中的关键字在进行一次更新,更新后的语法树会经过多轮处理转变最后的 SSA 中间代码。
目标代码生成与优化
不同机器的机器字长、寄存器等等都不一样,意味着在不同机器上跑的机器码是不一样的。最后一步的目的就是要生成能在不同 CPU 架构上运行的代码。
为了榨干机器的每一滴油水,目标代码优化器会对一些指令进行优化,例如使用移位指令代替乘法指令等。
这块实在没能力深入,幸好也不需要深入。对于应用层的软件开发工程师来说,了解一下就可以了。
链接过程
编译过程是针对单个文件进行的,文件与文件之间不可避免地要引用定义在其他模块的全局变量或者函数,这些变量或函数的地址只有在此阶段才能确定。
链接过程就是要把编译器生成的一个个目标文件链接成可执行文件。最终得到的文件是分成各种段的,比如数据段、代码段、BSS 段等等,运行时会被装载到内存中。各个段具有不同的读写、执行属性,保护了程序的安全运行。
这部分内容,推荐看《程序员的自我修养》和《深入理解计算机系统》。
Go 程序启动
仍然使用 hello-world 项目的例子。在项目根目录下执行:
go build -gcflags "-N -l" -o hello src/main.go
-gcflags"-N -l" 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
[qcrao@qcrao hello-world]$ gdb hello
进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:
同时,我们也得到了入口地址:0x450e20。
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AX
主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
TEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AX
继续跳转到 runtime·rt0_go(SB),位置:/usr/local/go/src/runtime/asm_amd64.s,代码:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// 省略很多 CPU 相关的特性标志位检查的代码
// 主要是看不懂,^_^
// ………………………………
// 下面是最后调用的一些函数,比较重要
// 初始化执行文件的绝对路径
CALL runtime·args(SB)
// 初始化 CPU 个数和内存页大小
CALL runtime·osinit(SB)
// 初始化命令行参数、环境变量、gc、栈空间、内存管理、所有 P 实例、HASH算法等
CALL runtime·schedinit(SB)
// 要在 main goroutine 上运行的函数
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
// 新建一个 goroutine,该 goroutine 绑定 runtime.main,放在 P 的本地队列,等待调度
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
MOVL $0xf1, 0xf1 // crash
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
参考文献里的一篇文章【探索 golang 程序启动过程】研究得比较深入,总结下:
检查运行平台的 CPU,设置好程序运行需要相关标志。
TLS 的初始化。
runtime.args、runtime.osinit、runtime.schedinit 三个方法做好程序运行需要的各种变量与调度器。
runtime.newproc 创建新的 goroutine 用于绑定用户写的 main 方法。
runtime.mstart 开始 goroutine 的调度。
最后用一张图来总结 go bootstrap 过程吧:
main 函数里执行的一些重要的操作包括:新建一个线程执行 sysmon 函数,定期垃圾回收和调度抢占;启动 gc;执行所有的 init 函数等等。
上面是启动过程,看一下退出过程:
当 main 函数执行结束之后,会执行 exit(0) 来退出进程。若执行 exit(0) 后,进程没有退出,main 函数最后的代码会一直访问非法地址:
exit(0)
for {
var x *int32
*x = 0
}
正常情况下,一旦出现非法地址访问,系统会把进程杀死,用这样的方法确保进程退出。
关于程序退出这一段的阐述来自群聊《golang runtime 阅读》,又是一个高阶的读源码的组织,github 主页见参考资料。
当然 Go 程序启动这一部分其实还会涉及到 fork 一个新进程、装载可执行文件,控制权转移等问题。还是推荐看前面的两本书,我觉得我不会写得更好,就不叙述了。
GoRoot 和 GoPath
GoRoot 是 Go 的安装路径。mac 或 unix 是在 /usr/local/go 路径上,来看下这里都装了些什么:
bin 目录下面:
pkg 目录下面:
Go 工具目录如下,其中比较重要的有编译器 compile,链接器 link:
GoPath 的作用在于提供一个可以寻找 .go 源码的路径,它是一个工作空间的概念,可以设置多个目录。Go 官方要求,GoPath 下面需要包含三个文件夹:
src
pkg
bin
src 存放源文件,pkg 存放源文件编译后的库文件,后缀为 .a;bin 则存放可执行文件。
Go 命令详解
直接在终端执行:
go
就能得到和 go 相关的命令简介:
和编译相关的命令主要是:
go build
go install
go run
go build
go build 用来编译指定 packages 里的源码文件以及它们的依赖包,编译的时候会到 $GoPath/src/package 路径下寻找源码文件。go build 还可以直接编译指定的源码文件,并且可以同时指定多个。
通过执行 go help build 命令得到 go build 的使用方法:
usage: go build [-o output] [-i] [build flags] [packages]
-o 只能在编译单个包的时候出现,它指定输出的可执行文件的名字。
-i 会安装编译目标所依赖的包,安装是指生成与代码包相对应的 .a 文件,即静态库文件(后面要参与链接),并且放置到当前工作区的 pkg 目录下,且库文件的目录层级和源码层级一致。
至于 build flags 参数, build,clean,get,install,list,run,test 这些命令会共用一套:
| 参数 | 作用 |
|---|---|
| -a | 强制重新编译所有涉及到的包,包括标准库中的代码包,这会重写 /usr/local/go 目录下的 .a 文件 |
| -n | 打印命令执行过程,不真正执行 |
| -p n | 指定编译过程中命令执行的并行数,n 默认为 CPU 核数 |
| -race | 检测并报告程序中的数据竞争问题 |
| -v | 打印命令执行过程中所涉及到的代码包名称 |
| -x | 打印命令执行过程中所涉及到的命令,并执行 |
| -work | 打印编译过程中的临时文件夹。通常情况下,编译完成后会被删除 |
我们知道,Go 语言的源码文件分为三类:命令源码、库源码、测试源码。
命令源码文件:是 Go 程序的入口,包含
func main()函数,且第一行用packagemain声明属于 main 包。库源码文件:主要是各种函数、接口等,例如工具类的函数。
测试源码文件:以
_test.go为后缀的文件,用于测试程序的功能和性能。
注意, go build 会忽略 *_test.go 文件。
我们通过一个很简单的例子来演示 go build 命令。我用 Goland 新建了一个 hello-world 项目(为了展示引用自定义的包,和之前的 hello-world 程序不同),项目的结构如下:
最左边可以看到项目的结构,包含三个文件夹:bin,pkg,src。其中 src 目录下有一个 main.go,里面定义了 main 函数,是整个项目的入口,也就是前面提过的所谓的命令源码文件;src 目录下还有一个 util 目录,里面有 util.go 文件,定义了一个可以获取本机 IP 地址的函数,也就是所谓的库源码文件。
中间是 main.go 的源码,引用了两个包,一个是标准库的 fmt;一个是 util 包,util 的导入路径是 util。所谓的导入路径是指相对于 Go 的源码目录 $GoRoot/src 或者 $GoPath/src 的下的子路径。例如 main 包里引用的 fmt 的源码路径是 /usr/local/go/src/fmt,而 util 的源码路径是 /Users/qcrao/hello-world/src/util,正好我们设置的 GoPath = /Users/qcrao/hello-world。
最右边是库函数的源码,实现了获取本机 IP 的函数。
在 src 目录下,直接执行 go build 命令,在同级目录生成了一个可执行文件,文件名为 src,使用 ./src 命令直接执行,输出:
hello world!
Local IP: 192.168.1.3
我们也可以指定生成的可执行文件的名称:
go build -o bin/hello
这样,在 bin 目录下会生成一个可执行文件,运行结果和上面的 src 一样。
其实,util 包可以单独被编译。我们可以在项目根目录下执行:
go build util
编译程序会去 $GoPath/src 路径找 util 包(其实是找文件夹)。还可以在 ./src/util 目录下直接执行 go build 编译。
当然,直接编译库源码文件不会生成 .a 文件,因为:
go build 命令在编译只包含库源码文件的代码包(或者同时编译多个代码包)时,只会做检查性的编译,而不会输出任何结果文件。
为了展示整个编译链接的运行过程,我们在项目根目录执行如下的命令:
go build -v -x -work -o bin/hello src/main.go
-v 会打印所编译过的包名字, -x 打印编译期间所执行的命令, -work 打印编译期间生成的临时文件路径,并且编译完成之后不会被删除。
执行结果:
从结果来看,图中用箭头标注了本次编译过程涉及 2 个包:util,command-line-arguments。第二个包比较诡异,源码里根本就没有这个名字好吗?其实这是 go build 命令检测到 [packages] 处填的是一个 .go 文件,因此创建了一个虚拟的包:command-line-arguments。
同时,用红框圈出了 compile, link,也就是先编译了 util 包和 main.go 文件,分别得到 .a 文件,之后将两者进行链接,最终生成可执行文件,并且移动到 bin 目录下,改名为 hello。
另外,第一行显示了编译过程中的工作目录,此目录的文件结构是:
可以看到,和 hello-world 目录的层级基本一致。command-line-arguments 就是虚拟的 main.go 文件所处的包。exe 目录下的可执行文件在最后一步被移动到了 bin 目录下,所以这里是空的。
整体来看, go build 在执行时,会先递归寻找 main.go 所依赖的包,以及依赖的依赖,直至最底层的包。这里可以是深度优先遍历也可以是宽度优先遍历。如果发现有循环依赖,就会直接退出,这也是经常会发生的循环引用编译错误。
正常情况下,这些依赖关系会形成一棵倒着生长的树,树根在最上面,就是 main.go 文件,最下面是没有任何其他依赖的包。编译器会从最左的节点所代表的包开始挨个编译,完成之后,再去编译上一层的包。
这里,引用郝林老师几年前在 github 上发表的 go 命令教程,可以从参考资料找到原文地址。
从代码包编译的角度来说,如果代码包 A 依赖代码包 B,则称代码包 B 是代码包 A 的依赖代码包(以下简称依赖包),代码包 A 是代码包 B 的触发代码包(以下简称触发包)。
执行
go build命令的计算机如果拥有多个逻辑 CPU 核心,那么编译代码包的顺序可能会存在一些不确定性。但是,它一定会满足这样的约束条件:依赖代码包 -> 当前代码包 -> 触发代码包。
顺便推荐一个浏览器插件 Octotree,在看 github 项目的时候,此插件可以在浏览器里直接展示整个项目的文件结构,非常方便:
到这里,你一定会发现,对于 hello-wrold 文件夹下的 pkg 目录好像一直没有涉及到。
其实,pkg 目录下面应该存放的是涉及到的库文件编译后的包,也就是一些 .a 文件。但是 go build 执行过程中,这些 .a 文件放在临时文件夹中,编译完成后会被直接删掉,因此一般不会用到。
前面我们提到过,在 go build 命令里加上 -i 参数会安装这些库文件编译的包,也就是这些 .a 文件会放到 pkg 目录下。
在项目根目录执行 go build-i src/main.go 后,pkg 目录里增加了 util.a 文件:
darwin_amd64 表示的是:
GOOS 和 GOARCH。这两个环境变量不用我们设置,系统默认的。
GOOS 是 Go 所在的操作系统类型,GOARCH 是 Go 所在的计算架构。
Mac 平台上这个目录名就是 darwin_amd64。
生成了 util.a 文件后,再次编译的时候,就不会再重新编译 util.go 文件,加快了编译速度。
同时,在根目录下生成了名称为 main 的可执行文件,这是以 main.go 的文件名命令的。
hello-world 这个项目的代码已经上传到了 github 项目 Go-Questions,这个项目由问题导入,企图串连 Go 的所有知识点,正在完善,期待你的 star。地址见参考资料【Go-Questions hello-world 项目】。
go install
go install 用于编译并安装指定的代码包及它们的依赖包。相比 go build,它只是多了一个 “安装编译后的结果文件到指定目录” 的步骤。
还是使用之前 hello-world 项目的例子,我们先将 pkg 目录删掉,在项目根目录执行:
go install src/main.go
或者
go install util
两者都会在根目录下新建一个 pkg 目录,并且生成一个 util.a 文件。
并且,在执行前者的时候,会在 GOBIN 目录下生成名为 main 的可执行文件。
所以,运行 go install 命令,库源码包对应的 .a 文件会被放置到 pkg 目录下,命令源码包生成的可执行文件会被放到 GOBIN 目录。
go install 在 GoPath 有多个目录的时候,会产生一些问题,具体可以去看郝林老师的 Go命令教程,这里不展开了。
go run
go run 用于编译并运行命令源码文件。
在 hello-world 项目的根目录,执行 go run 命令:
go run -x -work src/main.go
-x 可以打印整个过程涉及到的命令,-work 可以看到临时的工作目录:
从上图中可以看到,仍然是先编译,再连接,最后直接执行,并打印出了执行结果。
第一行打印的就是工作目录,最终生成的可执行文件就是放置于此:
main 就是最终生成的可执行文件。
总结
这次的话题太大了,困难重重。从编译原理到 go 启动时的流程,到 go 命令原理,每个话题单独抽出来都可以写很多。
幸好有一些很不错的书和博客文章可以去参考。这篇文章就作为一个引子,你可以跟随参考资料里推荐的一些内容去发散。
参考资料
【《程序员的自我修养》全书】https://book.douban.com/subject/3652388/
【面向信仰编程 编译过程概述】https://draveness.me/golang-compile-intro
【golang runtime 阅读】https://github.com/zboya/golangruntimereading
【Go-Questions hello-world 项目】https://github.com/qcrao/Go-Questions/tree/master/examples/hello-world
【雨痕大佬的 Go 语言学习笔记】https://github.com/qyuhen/book
【vim 以 16 进制文本】https://www.cnblogs.com/meibenjin/archive/2012/12/06/2806396.html
【Go 编译命令执行过程】https://halfrost.com/go_command/
【Go 命令执行过程】https://github.com/hyper0x/gocommandtutorial
【Go 词法分析】https://ggaaooppeenngg.github.io/zh-CN/2016/04/01/go-lexer-%E8%AF%8D%E6%B3%95%E5%88%86%E6%9E%90/
【曹大博客 golang 与 ast】http://xargin.com/ast/
【Golang 词法解析器,scanner 源码分析】https://blog.csdn.net/zhaoruixiang1111/article/details/89892435
【Gopath Explained】https://flaviocopes.com/go-gopath/
【Understanding the GOPATH】https://www.digitalocean.com/community/tutorials/understanding-the-gopath
【讨论】https://stackoverflow.com/questions/7970390/what-should-be-the-values-of-gopath-and-goroot
【Go 官方 Gopath】https://golang.org/cmd/go/#hdr-GOPATHenvironmentvariable
【Go package 的探索】https://mp.weixin.qq.com/s/OizVLXfZ6EC1jI-NL7HqeA
【Go 官方 关于 Go 项目的组织结构】https://golang.org/doc/code.html
【Go modules】https://www.melvinvivas.com/go-version-1-11-modules/
【Golang Installation, Setup, GOPATH, and Go Workspace】https://www.callicoder.com/golang-installation-setup-gopath-workspace/
【编译、链接过程链接】https://mikespook.com/2013/11/%E7%BF%BB%E8%AF%91-go-build-%E5%91%BD%E4%BB%A4%E6%98%AF%E5%A6%82%E4%BD%95%E5%B7%A5%E4%BD%9C%E7%9A%84%EF%BC%9F/
【1.5 编译器由 go 语言完成】https://www.infoq.cn/article/2015/08/go-1-5
【Go 编译过程系列文章】https://www.ctolib.com/topics-3724.html
【曹大 go bootstrap】https://github.com/cch123/golang-notes/blob/master/bootstrap.md
【golang 启动流程】https://blog.iceinto.com/posts/go/start/
【探索 golang 程序启动过程】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2golang%E7%A8%8B%E5%BA%8F%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B/
【探索 goroutine 的创建】http://cbsheng.github.io/posts/%E6%8E%A2%E7%B4%A2goroutine%E7%9A%84%E5%88%9B%E5%BB%BA/
本文由 简悦 SimpRead 转码, 原文地址 all1024.com
学习 Golang 有一段时间了,自己看着各种教程也码了些 demo。
本文最后编辑于 前,其中的内容可能需要更新。
学习
Golang有一段时间了,自己看着各种教程也码了些demo。其实接触了这么多语言,当因为工作、项目、兴趣所驱在短时间切换一门编程语言时,并不会太难上手,甚至会对了解一些很雷同的基础语法感到枯燥,但这是必经之路。对于一个技术爱好者而言,技术广度、技术深度、技术新特性等往往是最好的兴奋剂。今天这篇文章主要结合最近的资料学习,对Go语言的运行机制及Go程序的运作进行一些稍微深入的分析及总结,对Go的启动和执行流程建立简单的宏观认知~
为什么 Go 语言适合现代的后端编程环境?
- 服务类应用以 API 居多,IO 密集型,且网络 IO 最多;
- 运行成本低,无 VM。网络连接数不多的情况下内存占用低;
- 强类型语言,易上手,易维护;
为什么适合基础设施?
k8s、etcd、istio、docker已经证明了 Go 的能力
一、理解可执行文件
1. 基本实验环境准备
使用docker构建基础环境
FROM centos
RUN yum install golang -y \
&& yum install dlv -y \
&& yum install binutils -y \
&& yum install vim -y \
&& yum install gdb -y
2. Go 语言的编译过程
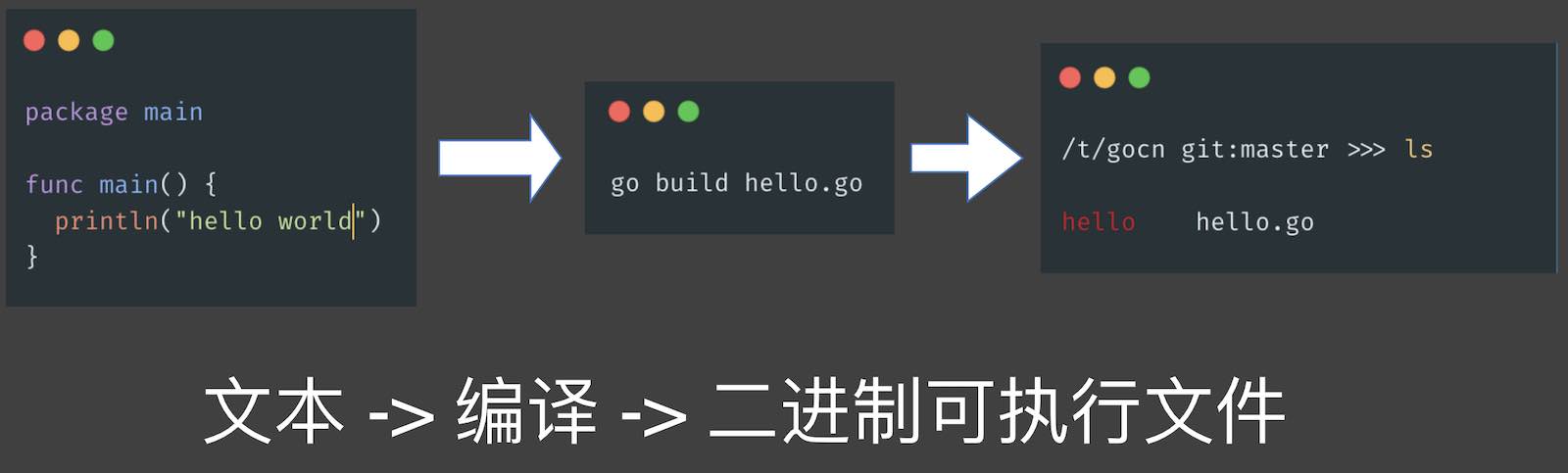
Go 程序的编译过程:文本 -> 编译 -> 二进制可执行文件
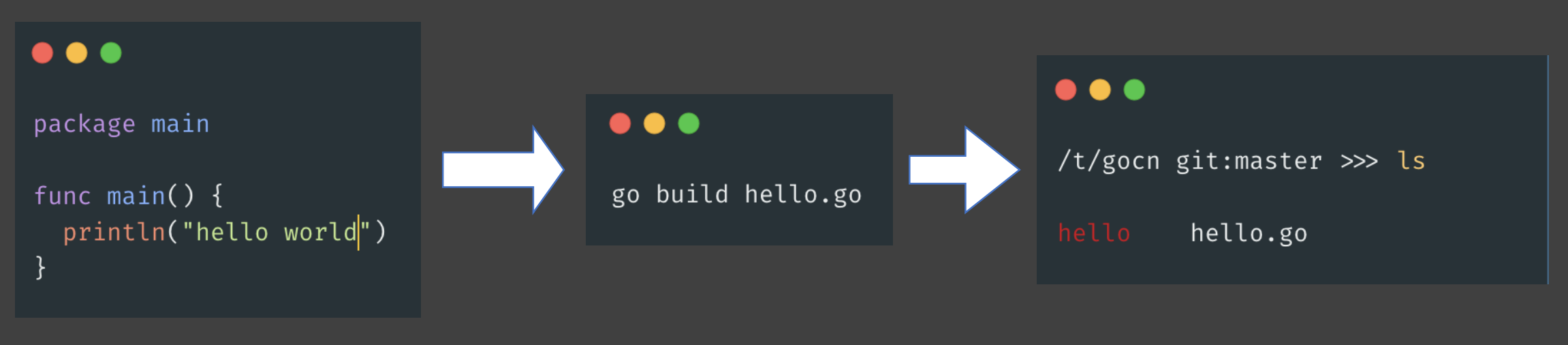
编译:文本代码 -> 目标文件(.o, .a)
链接:将目标文件合并为可执行文件
使用go build -x xxx.go可以观察这个过程

3. 不同系统的可执行文件规范
可执行文件在不同的操作系统规范不一样

以Linux的可执⾏⽂件ELF(Executable and Linkable Format) 为例,ELF 由⼏部分构成:
- ELF header
- Section header
- Sections
操作系统执行可执行文件的步骤(Linux 为例):

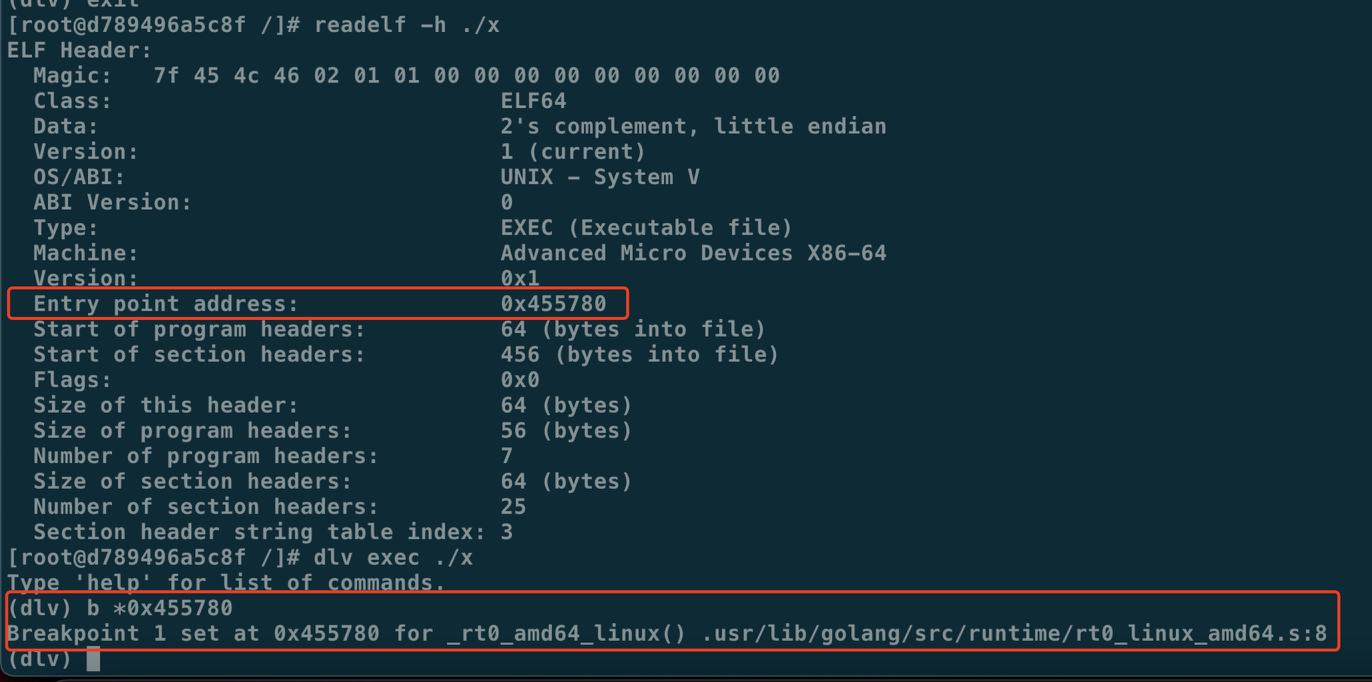
4. 如何寻找 Go 进程的入口
通过entry point找到 Go进程的执⾏⼊⼝,使⽤readelf。进一步找到Go进程要从哪里启动了~
二、Go 进程的启动与初始化
1. 计算机如何执⾏我们的程序

CPU⽆法理解⽂本,只能执⾏⼀条⼀条的⼆进制机器码指令,每次执⾏完⼀条指令,pc寄存器就指向下⼀条继续执⾏。
在 64 位平台上 pc 寄存器 = rip。
计算机会自上而下,依次执行汇编指令:

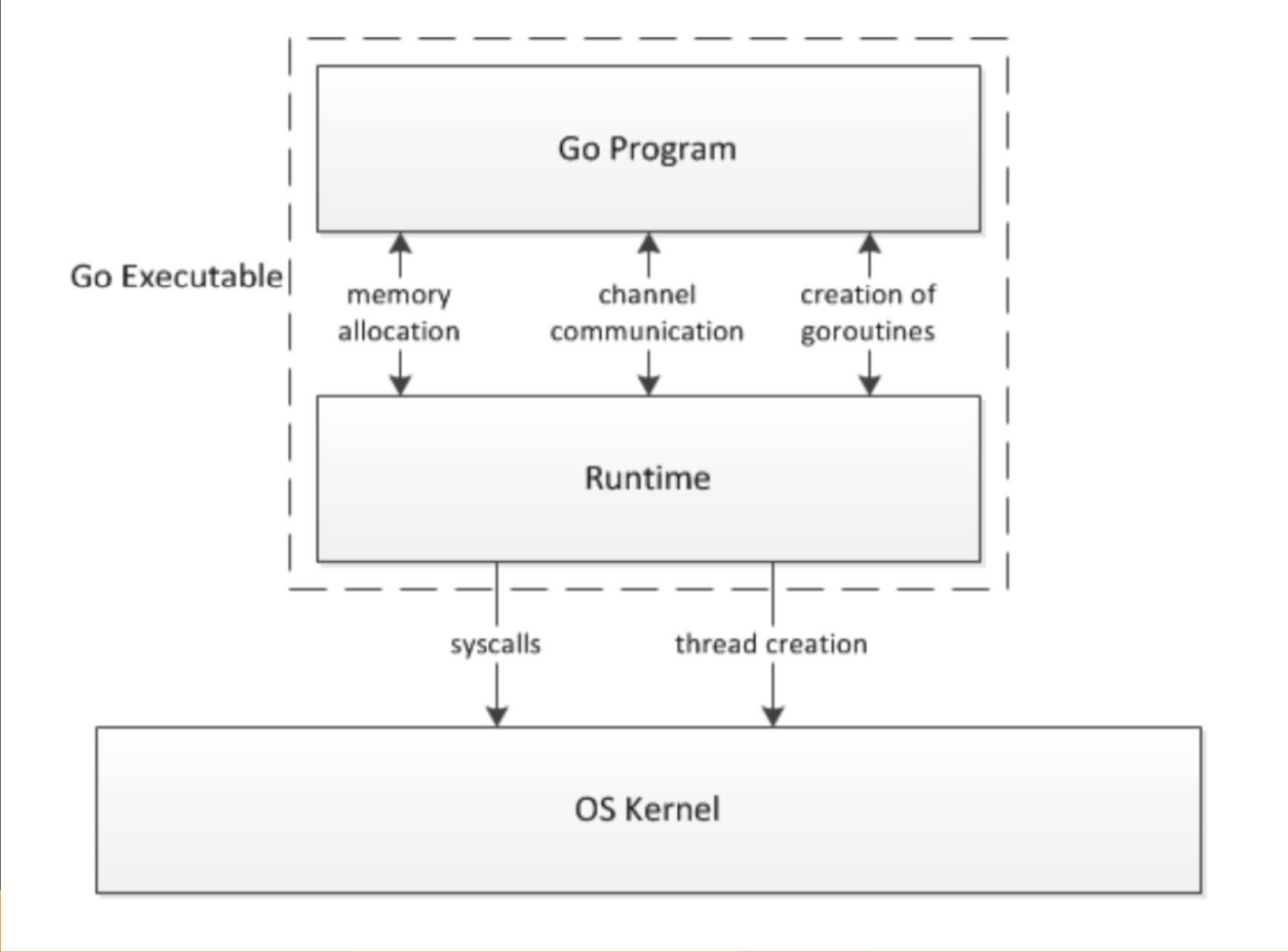
2. Runtime 是什么 & Go 语言的 Runtime
Go 语⾔是⼀⻔有runtime的语⾔,那么runtime是什么?

可以认为runtime是为了实现额外的功能,⽽在程序运⾏时⾃动加载 / 运⾏的⼀些模块。
Go 语言中,运行时、操作系统和程序员定义代码之间的关系如下图:
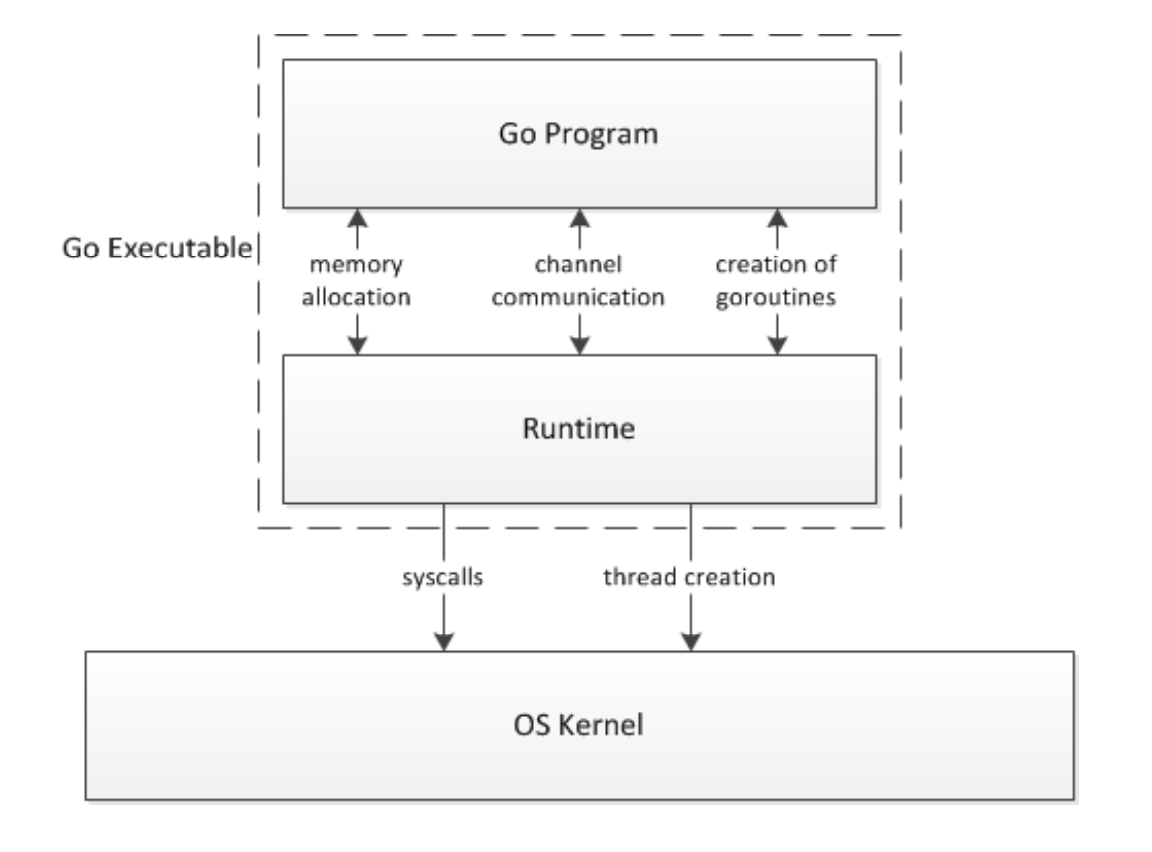
在 Go 语言中,runtime主要包括:
Scheduler:调度器管理所有的 G,M,P,在后台执⾏调度循环Netpoll:⽹络轮询负责管理⽹络 FD 相关的读写、就绪事件Memory Management:当代码需要内存时,负责内存分配⼯作Garbage Collector:当内存不再需要时,负责回收内存
这些模块中,最核⼼的就是 Scheduler,它负责串联所有的runtime 流程。
通过 entry point 找到 Go 进程的执⾏⼊⼝:
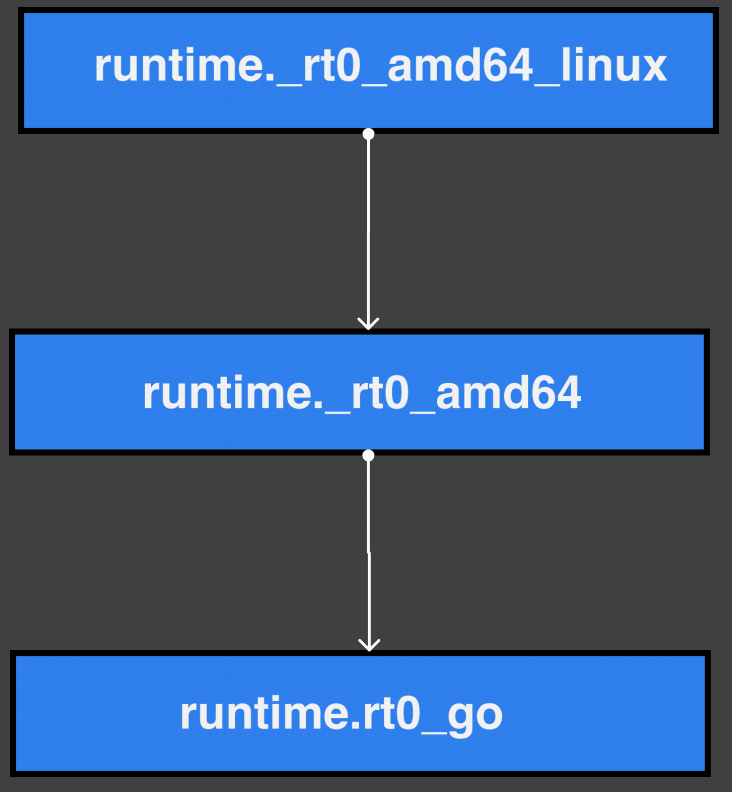
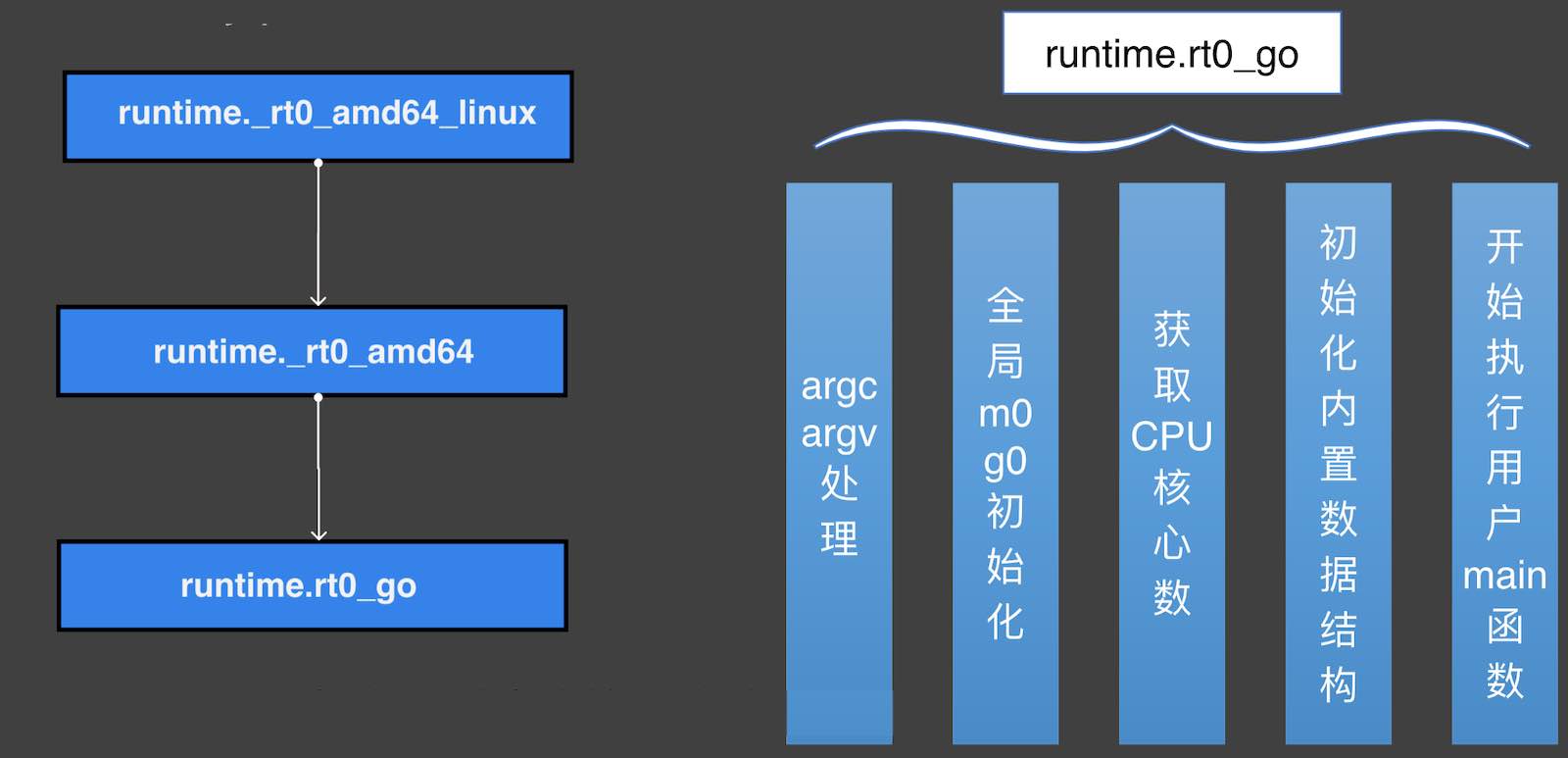
runtime.rt0_go的相关处理过程:
- 开始执行用户
main函数(从这里开始进入调度循环) - 初始化内置数据结构
- 获取 CPU 核心数
- 全局
m0、g0初始化 argc、argv处理
m0为 Go 程序启动后创建的第一个线程
三、调度组件与调度循环
1. Go 的生产 - 消费流程概述
每当写下:
go func() {
println("hello alex")
}()
的时候,到底发生了什么?这里其实就是向runtime提交了一个计算任务,func里面所裹挟的代码,就是这个计算任务的基本内容~
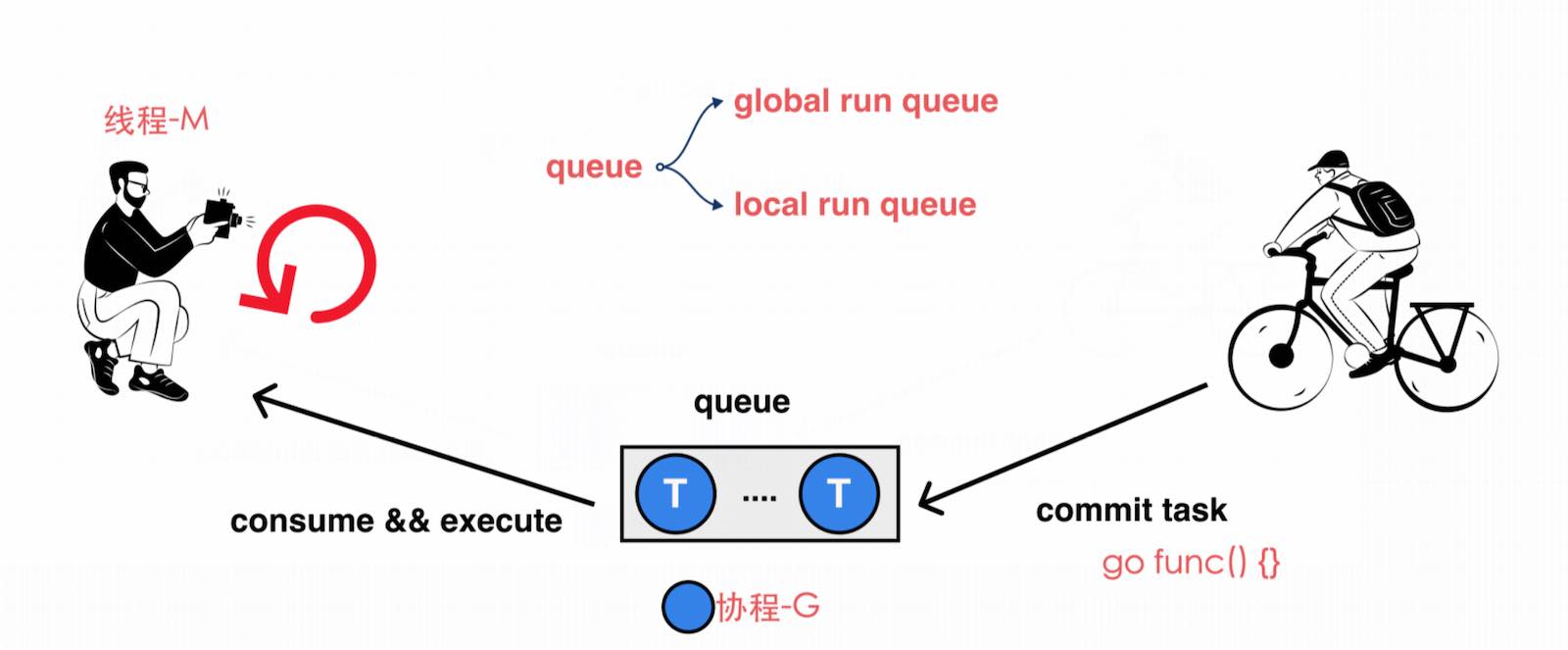
Go的调度流程本质上就是一个生产 - 消费流程,下图为生产消费的概况流程:
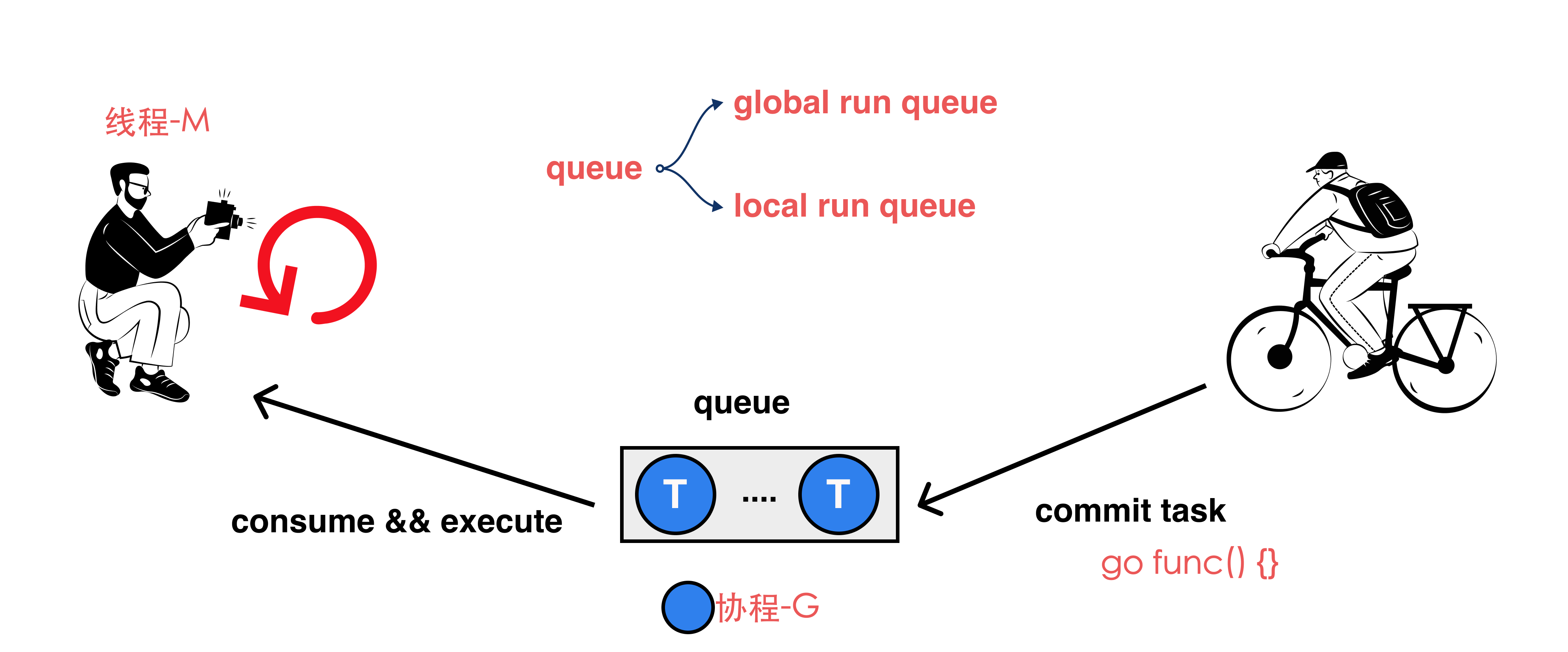
- 右边的生产者就是每次
go func() {}的时候提交的任务; - 中间的为队列,发送的任务会被打包成一个
协程G,即为goroutine; goroutine会进入到这个队列,而另一端进行消费的就是线程,线程是在循环里面执行消费的操作的;- 中间的队列主要会分为 2 部分,分别是
本地队列和全局队列
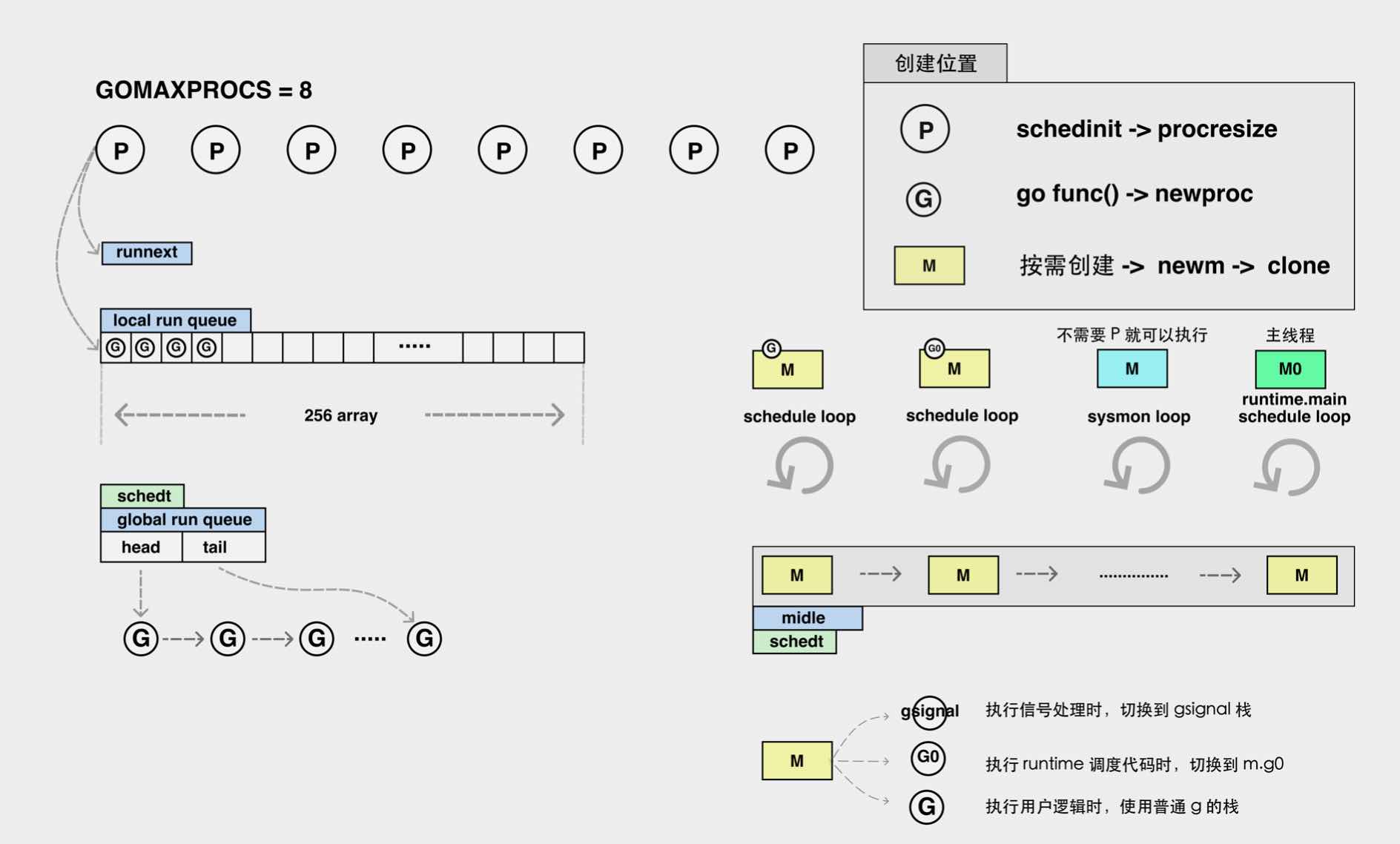
2. Go 的调度组件 P、G、M 结构
先整体给 P、G、M 下一个定义:
- G:
goroutine,⼀个计算任务。由需要执⾏的代码和其上下⽂组成,上下⽂包括:当前代码位置,栈顶、栈底地址,状态等。 - M:
machine,系统线程,执⾏实体,想要在CPU上执⾏代码,必须有线程,与C 语⾔中的线程相同,通过系统调⽤clone来创建。 - P:
processor,虚拟处理器,M 必须获得 P 才能执⾏代码,否则必须陷⼊休眠 (后台监控线程除外),你也可以将其理解为⼀种token,有这个token,才有在物理 CPU 核⼼上执⾏的权⼒。
本节的内容全部介绍完后回顾这几个概念,就会觉得相对好理解一些~
整体的结构图如下:
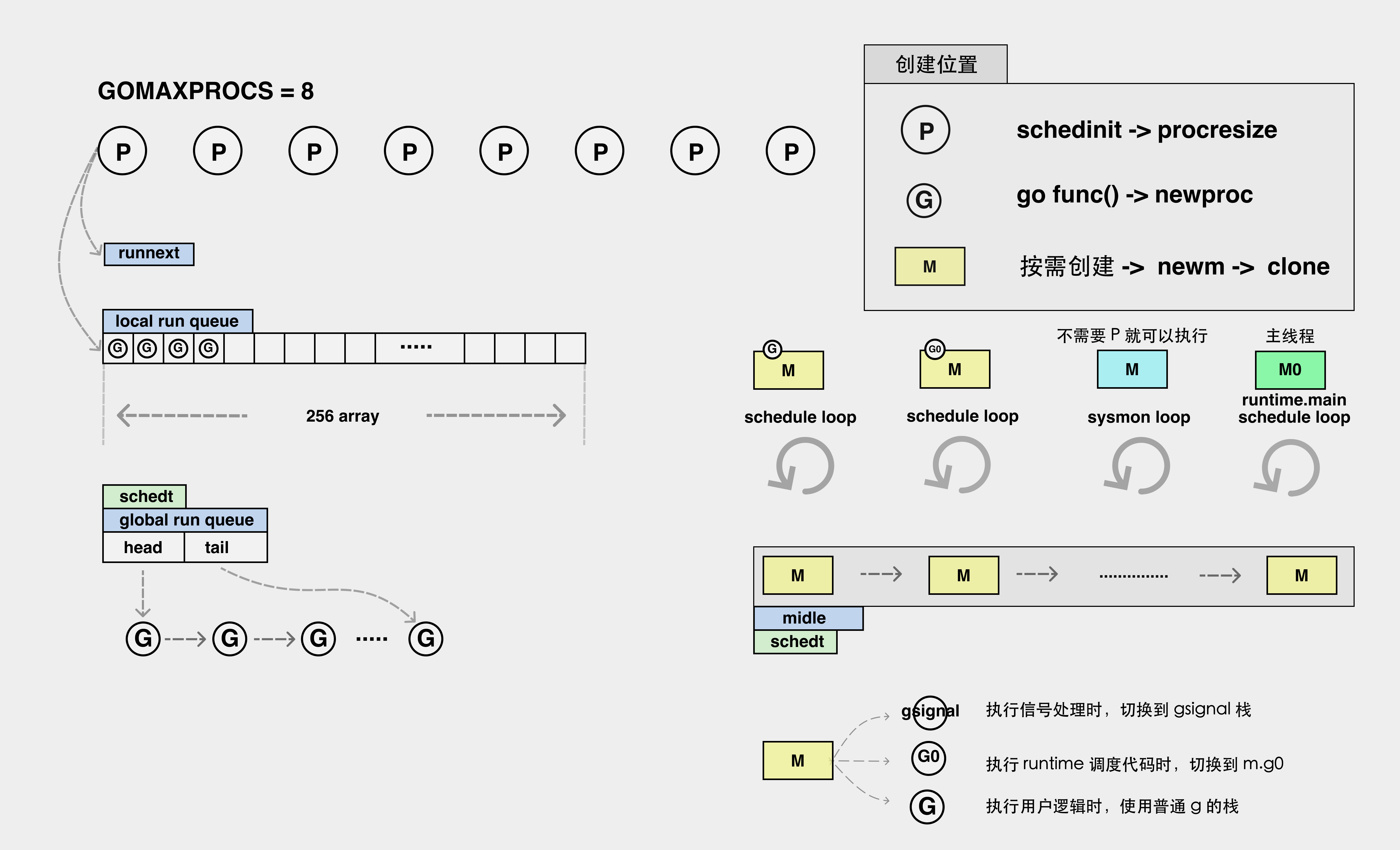
- 右边的蓝色、黄色、绿色的
M即为线程,大部分线程是一直在执行一个调度循环的,调度循环简单就是指线程要去左边的任务队列里(local run queue&global run queue)把任务拿出来然后执行的反复的操作; - 当然在整个过程中,线程是按需创建的,因此有一部分线程可能是空闲的,这些线程会被放在一个叫做
midle的队列中来进行管理,当没有可用的空闲线程时候就会在midle里面寻找使用; - 我们可以看到上图中,除了
local run queue(本地队列)和global run queue(全局队列),还有一个runnext的结构,而runnext与local run queue本质上都是为了解决程序的局部性问题**(程序的局部性原理:最近调用的一次代码很有很可能会马上被再一次调用,整体分为代码的局部性和数据的局部性)** ,我们一般不希望所有的生产都进入到全局的global run queue中; - 如果所有的线程消费的都是
global run queue的话,那么还需要进行额外加锁设计。这就是为什么会分为local run queue和global run queue的原因。
3. Go 的生产 - 消费详解
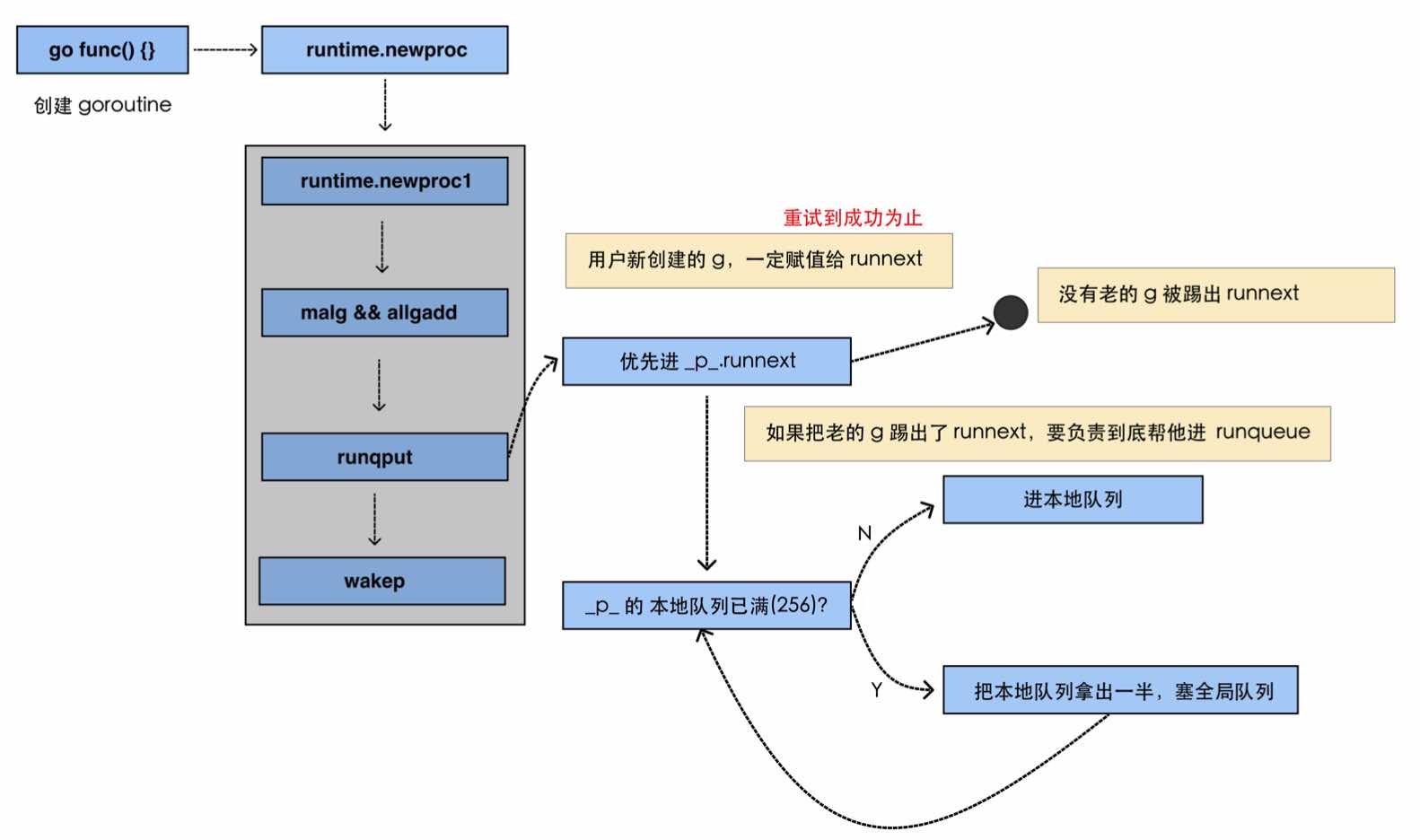
goroutine的生产端(runnext、local run queue、global run queue的过程)
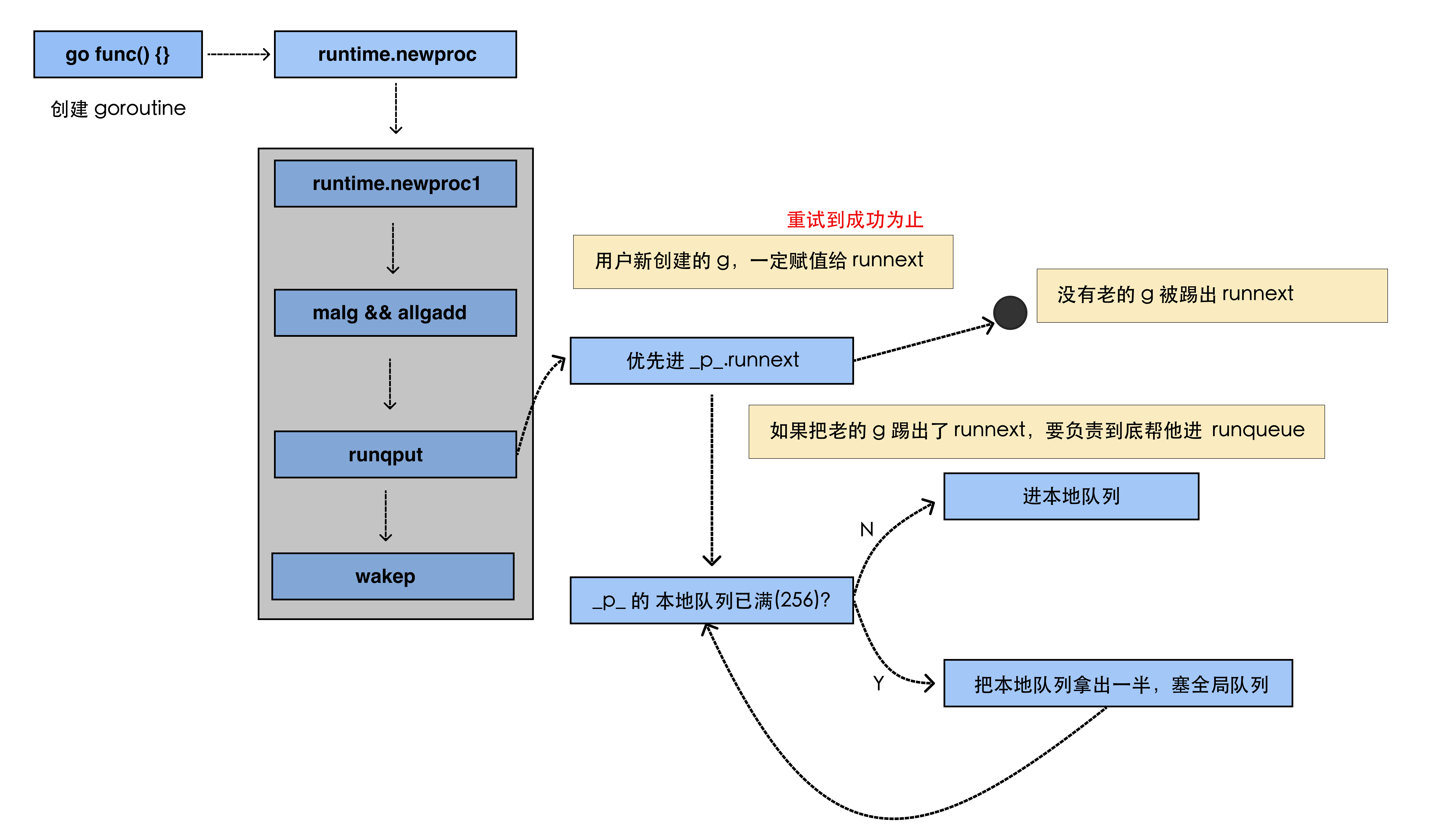
- 左上角会创建一个
goroutine,而这个goroutine会创建一个runtime,即通过runtime.newproc生成一个 G; - 对于
G的队列而言,runnext的优先级是最高的,首先会进入到runnext中; - 但新的
G进去,有可能会导致老的G被挤出,此时需要进行善后工作,老的G会进入到本地队列,而如果本地队列也已经满了的话,就会把本地队列拿出一半,塞给全局队列,以此循环; - 注意:
runnext本质上并不是队列,而是一个含有一个元素的指针,为了方便理解,将其与另外的本地队列(本质上是一个数组,且只有256的长度)和全局队列(本质上是一个链表)叫法一致。
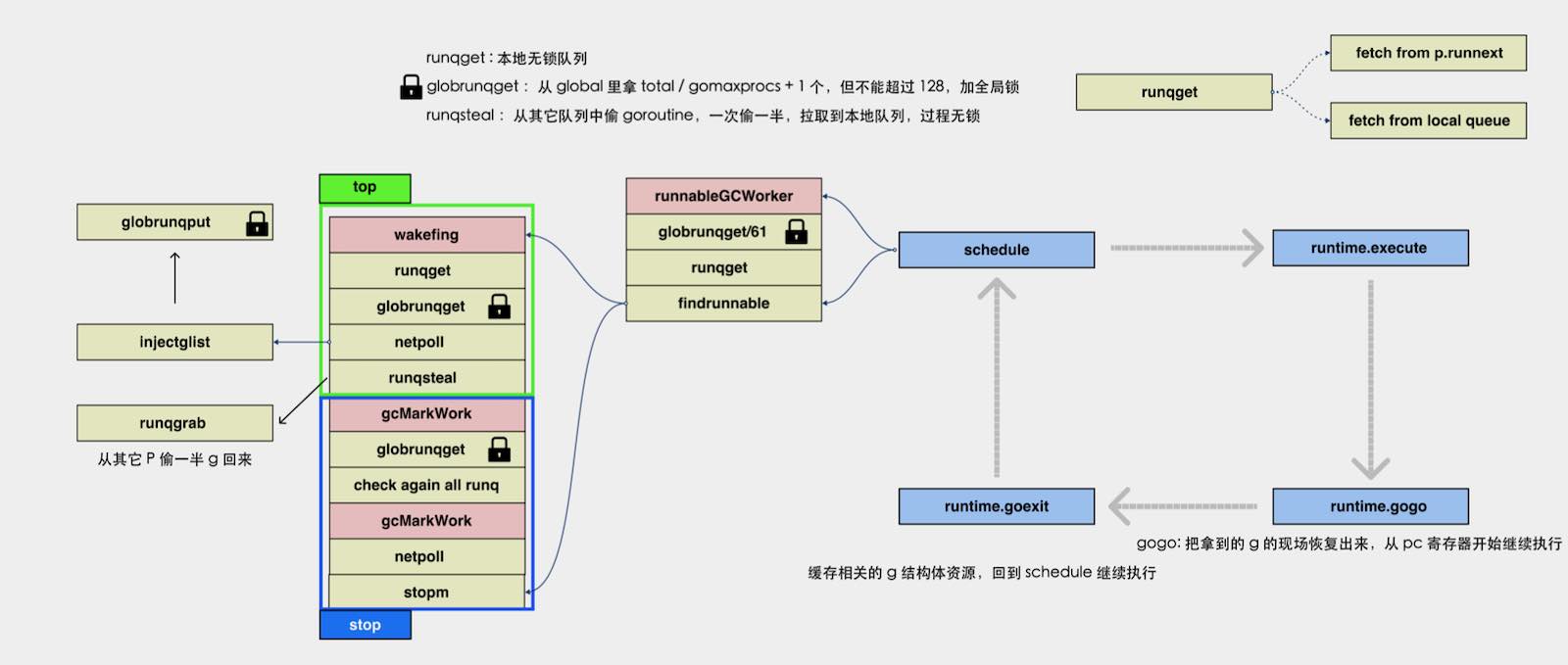
goroutine的消费端
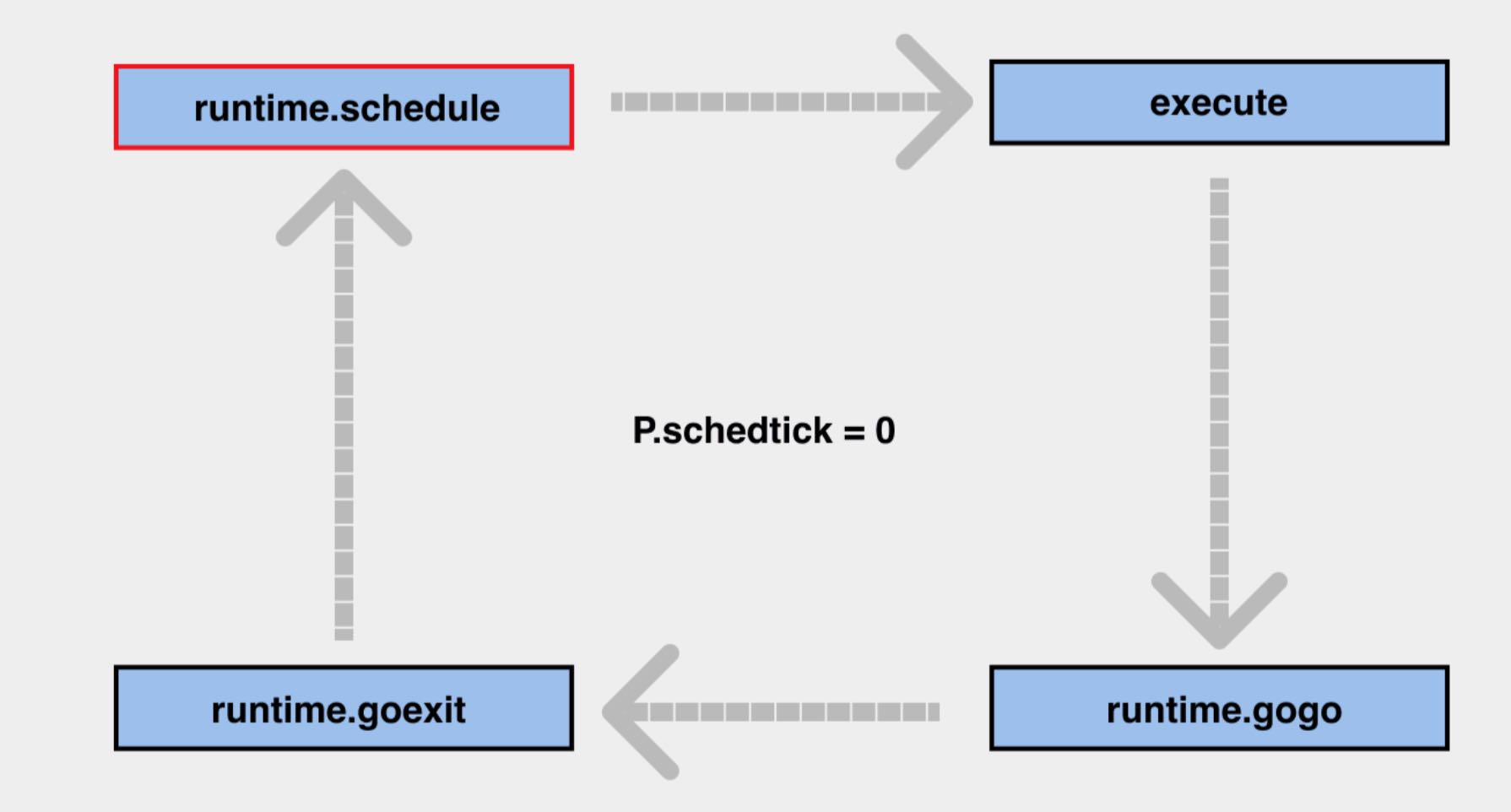
- 消费端本质上就是多个线程在反复执行一个循环,这个循环是从队列里面取值,上图右边的蓝色块指的就是标准的
调度循环的流程,即 runtime 里面的 4 个函数:runtime.schedule、runtime.execute、runtime.goexit、runtime.gogo; - 图中红色的区域是
垃圾回收gc相关的逻辑,schedule左边的 3 个黄色框,都为获取 G 的函数,如果schedule左边的任意一个函数返回一个 G 给schedule,右边的循环就会一直执行; - 在这些函数中,
globalrunqget/61指的就是会定期 61 次执行,去全局队列里面检索获取一个 G,防止在全局队列里面的 G 过度延迟; - 如果全局的 G 没有获取到,或者当前不需要获取全局的 G,就会从
本地队列进行获取(优先获取runnext),而本地队列的获取就是通过runqget这个函数做到的; - 如果还是没有获取到 G 的话,就会去执行
findrunnable函数,这个函数整体分为上下两部分,分别叫top和stop。top部分的函数功能,主要就是再次尝试依次从本地队列->全局队列获取 G,如果依然获取不到,就使用netpoll进行网络轮询情况的查看,如果在这里能找到 G,就将 G 放在全局队列里面,如果依然获取不到,就使用runqsteal从其他的 P 中偷一半 G 回来,这个有点像Work stealing的原理(runqsteal -> runqgrab); - 如果执行完整个
top部分依然获取不到 G,就说明 M 没有机会得到执行了,那么就开始执行stop部分,即线程的休眠流程,但在stopm执行之前,还是会再次检查一遍 G 的存在,确认无误后,就会将线程休眠。 - 需要注意的是:M 执⾏调度循环时,必须与⼀个 P 绑定;所有
global操作均需要加锁。
下面再单独将右边的调度循环过程摘出来描述一下:
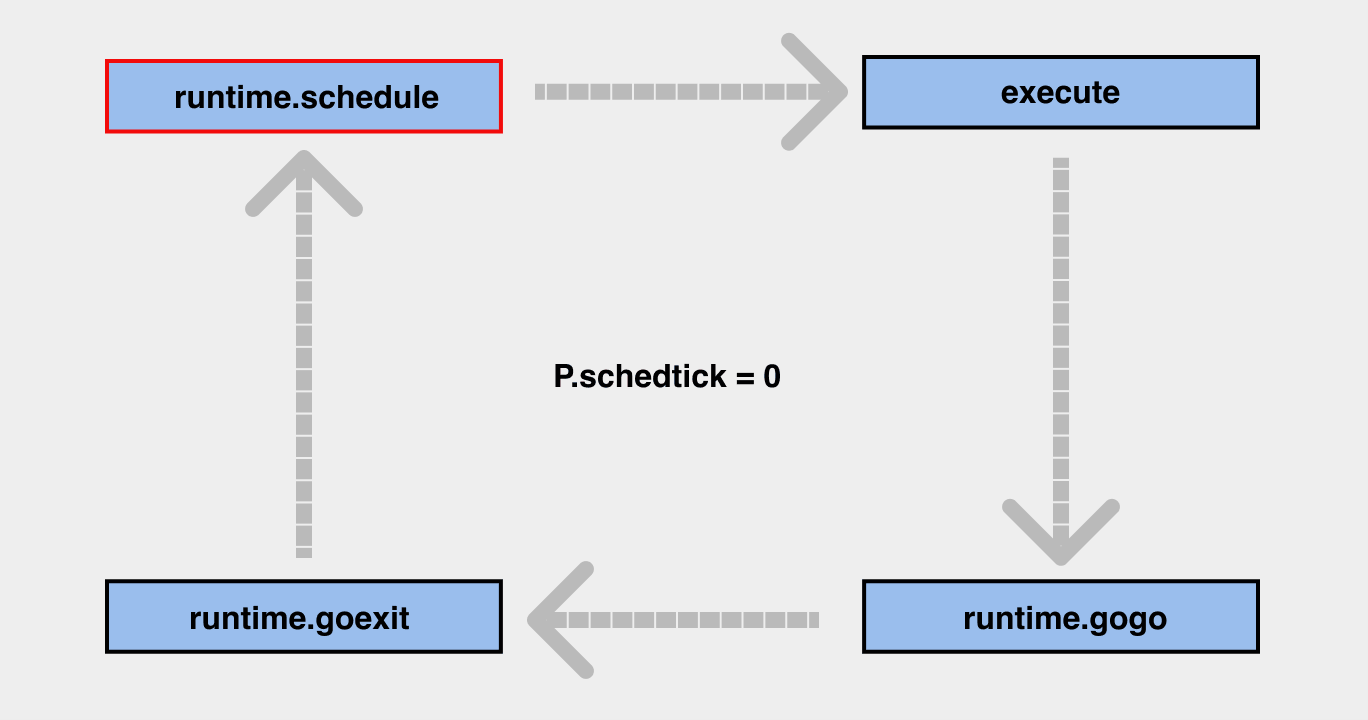
- 在上面的
调度循环中,最重要的就是schedule,它可以从相关的语言中去寻找正在执行的任务; - 当
schedule获取到 G 后,就进行execute流程(执行 go 的代码),gogo会把拿到的 G 的现场回复出来,从 PC 寄存器开始继续执行,goexit会结束当前的一次流程,并缓存相关的 G 结构体资源,然后回到schedule继续执行循环; - 在调度循环的过程中,会存在一个
P.scheditick的字段,用来记录调度循环已经执行了多少次,用于globrunnqget/61等判定中。当执行到execute的时候,P.scheditick就会+1。
前面介绍的就是调度循环及调度组件的内容,但 Go 仅仅能够处理正常情况是不行的,如果程序中有阻塞的话,需要避免线程阻塞~
四、处理阻塞
1. Go 语言中常见的阻塞情况
channel

time.Sleep

网络读

网络写

select 语句

锁

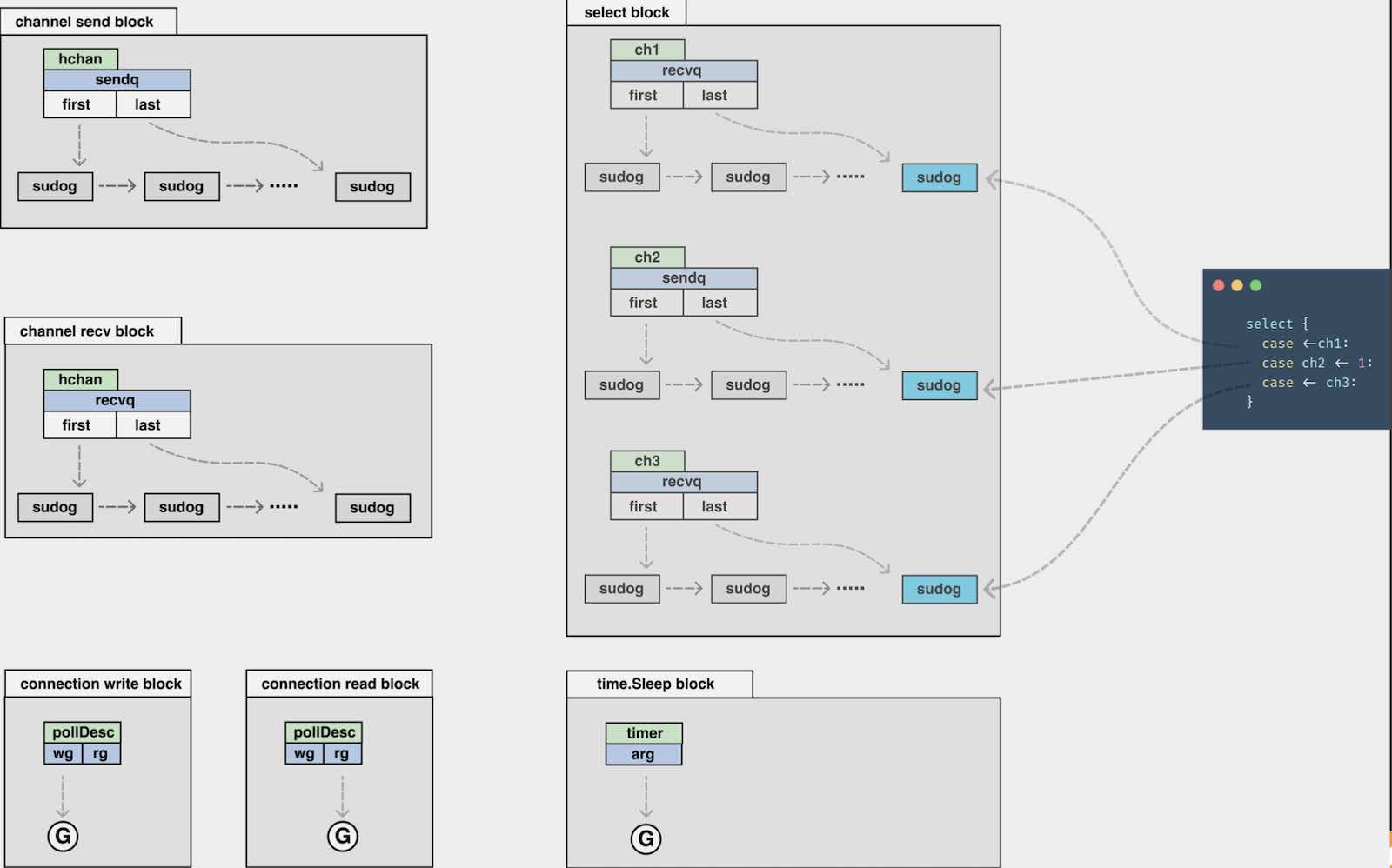
以上的 6 种阻塞,阻塞调度循环,⽽是会把 goroutine 挂起所谓的挂起,其实让 G 先进某个数据结构,待 ready 后再继续执⾏,不会占⽤线程。
这时候,线程会进⼊ schedule,继续消费队列,执⾏其它的 G
2. 各类阻塞中 G 是如何挂起的
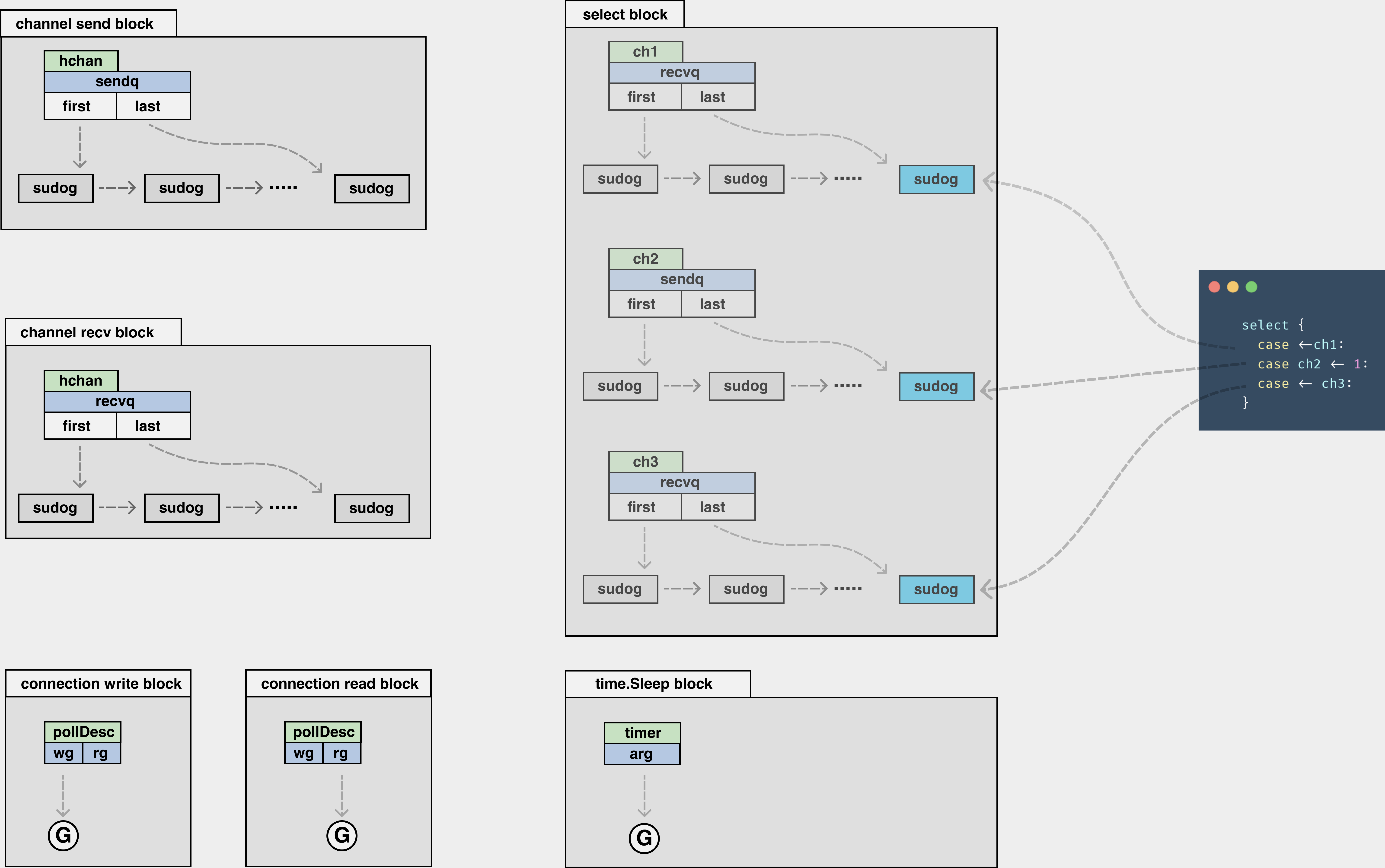
- channel 发送:如果阻塞了,会有一个
sendq等待队列,将 G 打包为sudog的数据结构,塞在了等待结构中; - channel 接收:如果阻塞了,会有一个
recvq等待队列,将 G 打包为sudog的数据结构,塞在了等待结构中; - 链接的写阻塞:G 会挂在底层
pollDesc的wg中; - 链接的读阻塞:G 会挂在底层
pollDesc的rg中; - select 阻塞:以图中的 3 个 channel 为例,会有 3 个
sendq或者是recvq队列,G 则打包为sudog挂在这些队列的尾部; - time.Sleep 阻塞:将 G 挂在
timer结构的一个参数上。
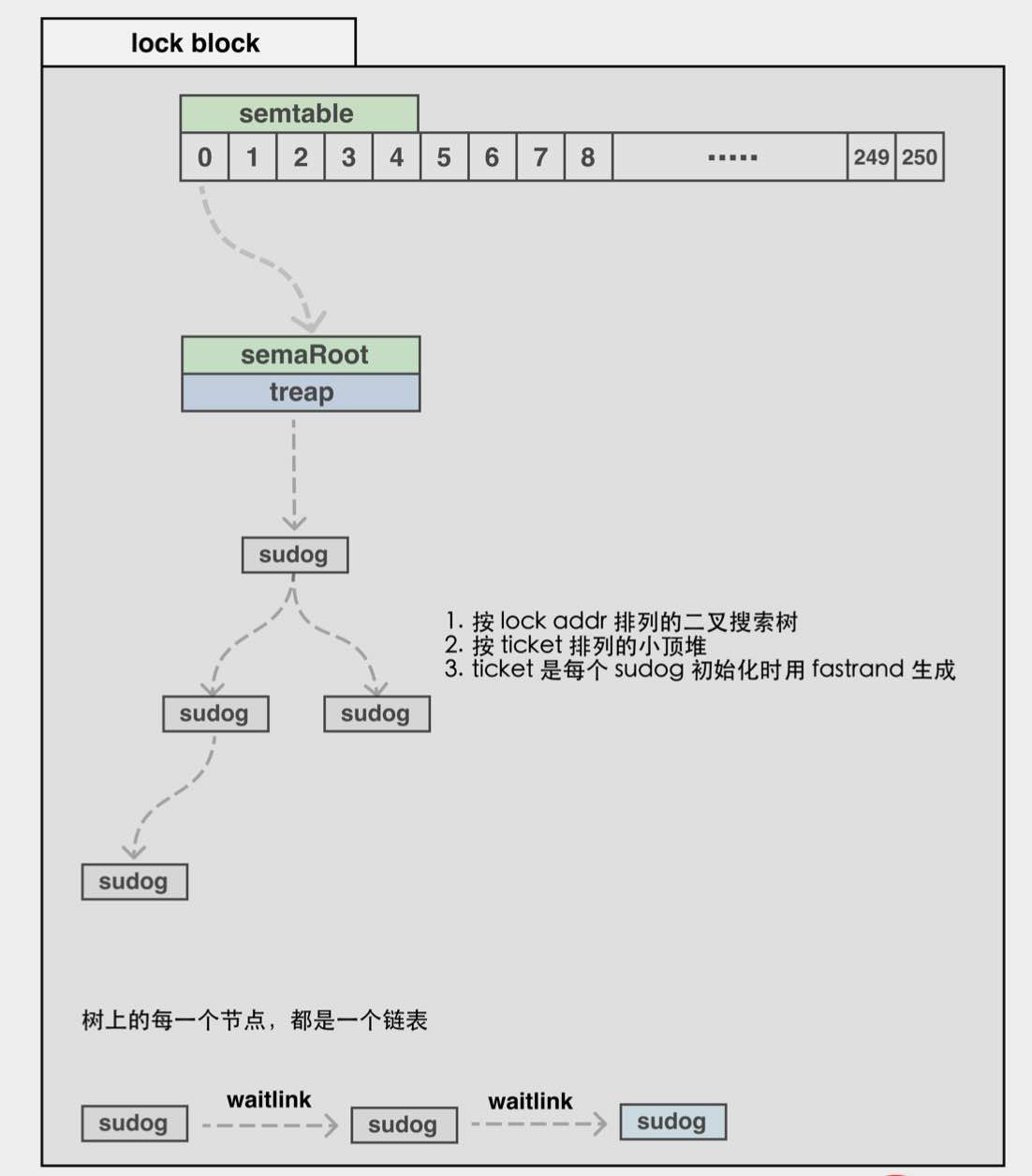
由于锁的阻塞相对特殊,单独拿出来说。
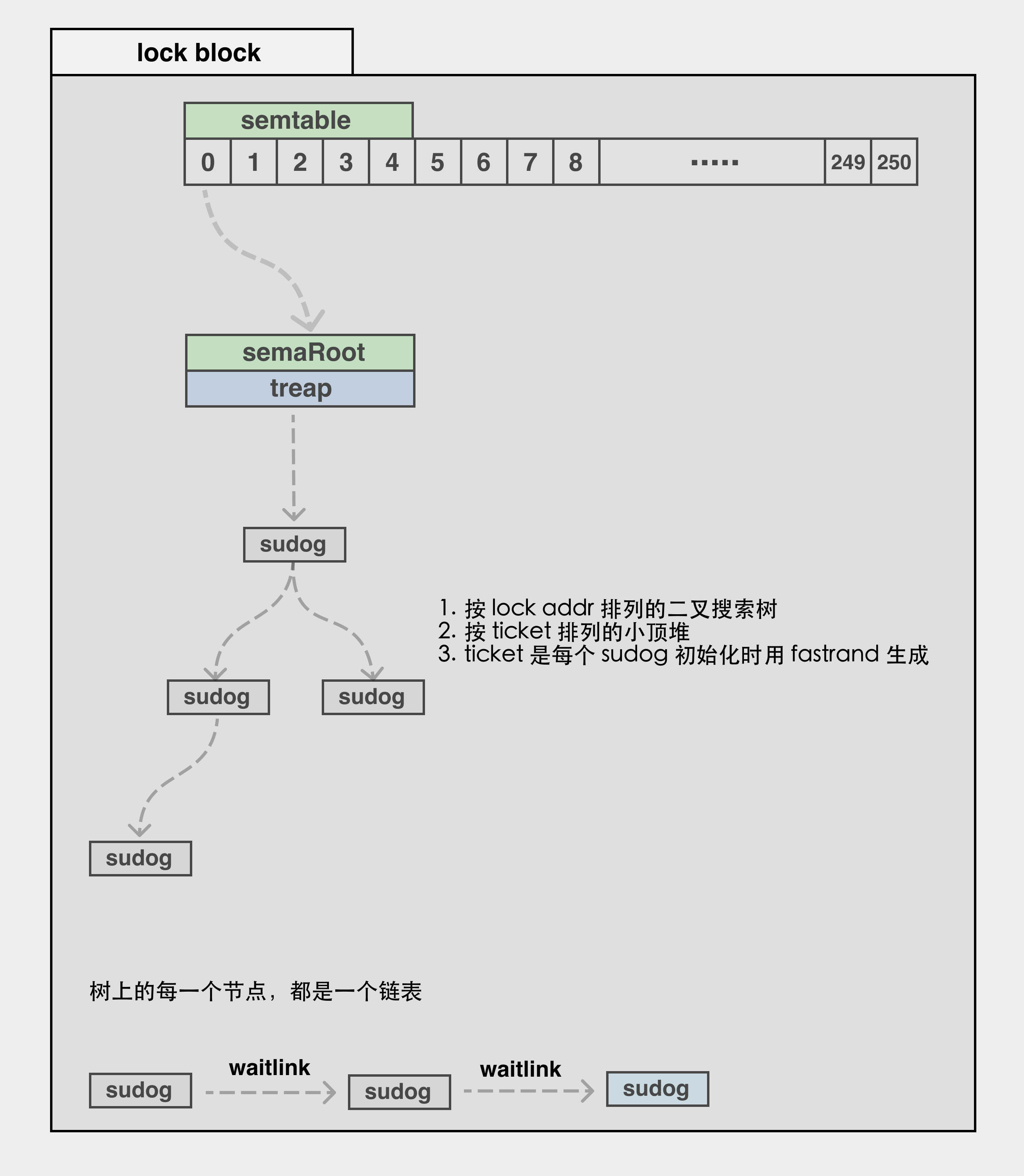
- 和前面的集中阻塞情况相似的是,锁的阻塞依然会将 G 打包为
sudog,会停留在树堆的结构中,树堆是一个二叉平衡树,且其中的每一个节点就是一个链表;
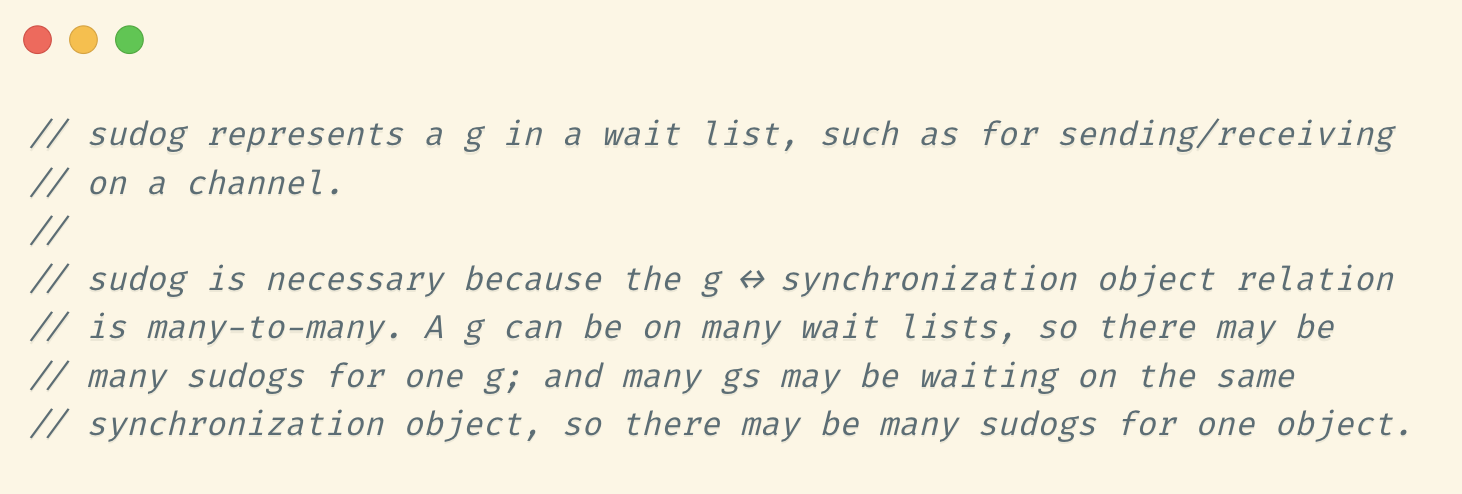
根据上面的介绍,我们可以看到,有些挂起等待结构是sudog而有些是G,为什么会这样呢?
因为,⼀个 G 可能对应多个 sudog,⽐如⼀个 G 会同时 select 多个channel,在runtime中有对这里解读的注释:
3. runtime 无法处理的阻塞
CGO
阻塞在syscall上
在执⾏ c 代码,或者阻塞在 syscall 上时,必须占⽤⼀个线程
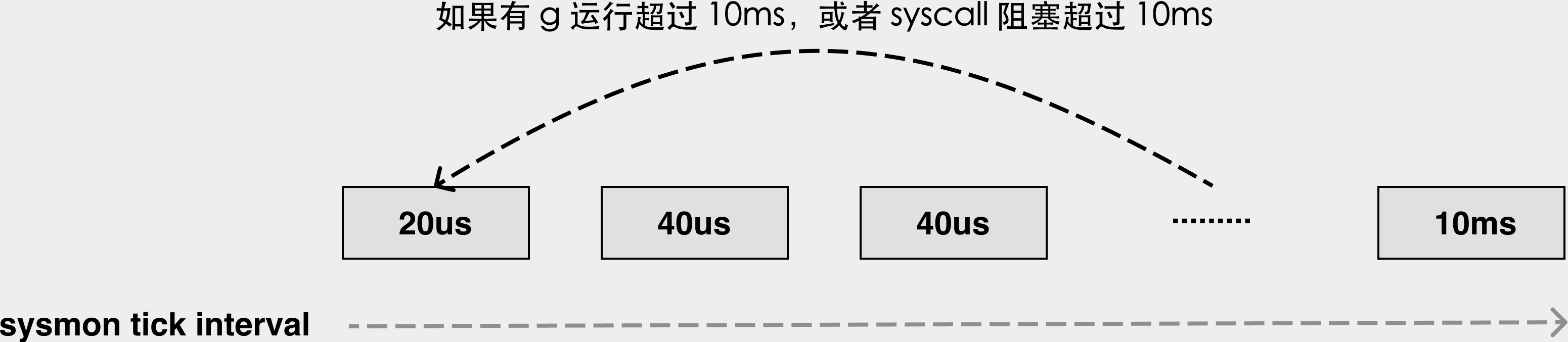
4. sysmon
sysmon: system monitor
sysmon在后台具有⾼优先级,在专有线程中执⾏,不需要绑定 P 就可以执⾏。
sysmon主要有 3 个作用:
checkdead—> 用于检查是否当前的所有线程都被阻塞住了,如果所有线程死锁,说明程序写的有问题,需要直接崩溃提示。对于网络应用而言,一般不会触发。常见的误解是:这个可以检查死锁;netpoll—> 将 G 插入到全局队列里面;retake—> 如果是syscall卡了很久,那就把P从M上剥离 (handoffp);在go1.14以后,如果是⽤户 G 运⾏很久了,那么发信号抢占。
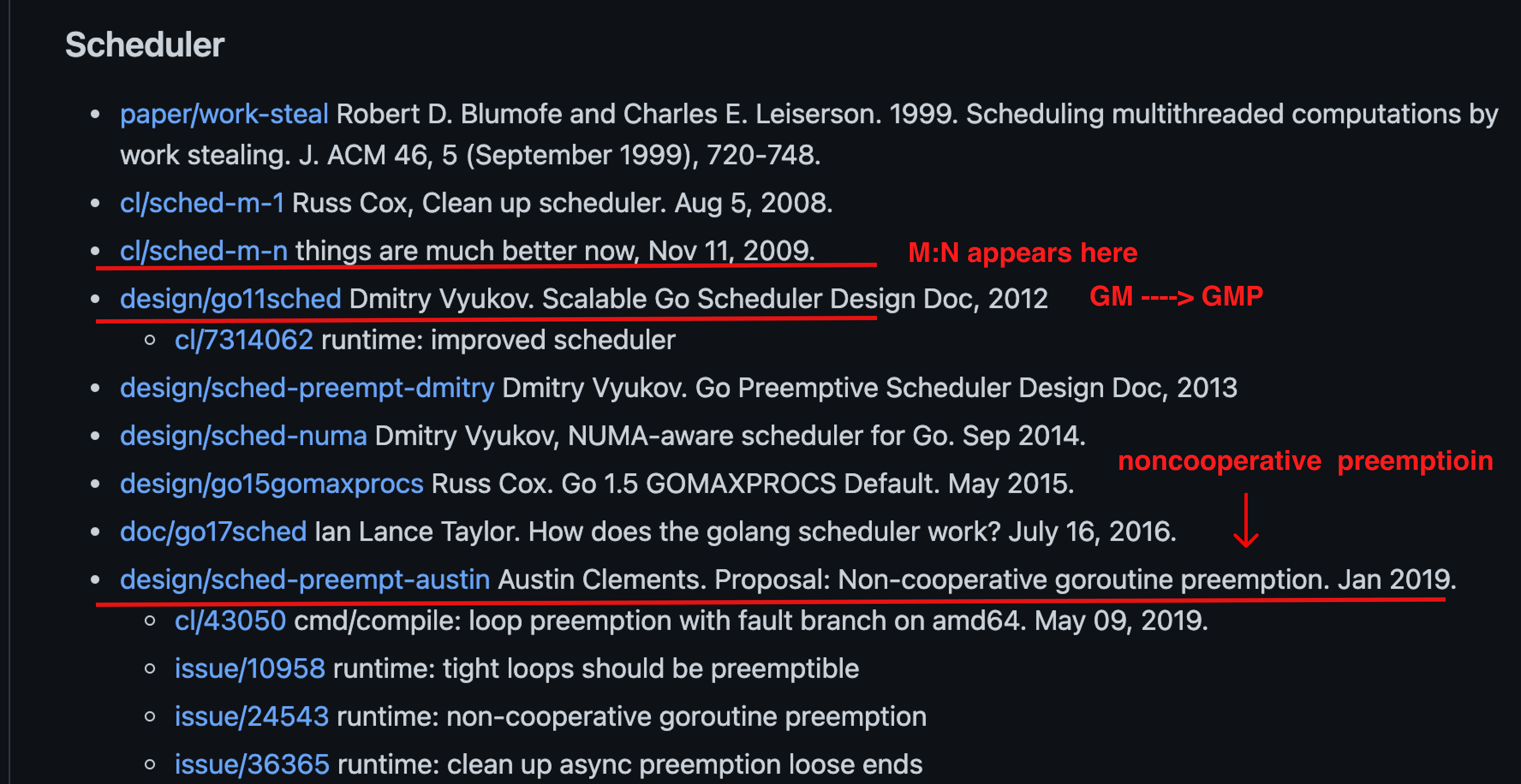
五、调度器的发展历史
六、知识点总结
1. 可执⾏⽂件 ELF:
- 使⽤
go build -x观察编译和链接过程 - 通过
readelf -H中的entry找到程序⼊⼝ - 在
dlv 调试器中b *entry_addr找到代码位置
2. 启动流程:
- 处理参数 -> 初始化内部数据结构 -> 主线程 -> 启动调度循环
3. Runtime 构成:
Scheduler、Netpoll、内存管理、垃圾回收
4. GMP:
- M,任务消费者;G,计算任务;P,可以使⽤
CPU的token
5. 队列:
- P 的本地
runnext字段 -> P 的local run queue->global run queue,多级队列减少锁竞争
6. 调度循环:
- 线程 M 在持有 P 的情况下不断消费运⾏队列中的 G 的过程。
7. 处理阻塞:
- 可以接管的阻塞:
channel 收发,加锁,⽹络连接读/写,select - 不可接管的阻塞:
syscall,cgo,⻓时间运⾏需要剥离 P 执⾏
8. sysmon:
- ⼀个后台⾼优先级循环,执⾏时不需要绑定任何的 P ,负责:
- 检查是否已经没有活动线程,如果是,则崩溃;
- 轮询
netpoll; - 剥离在
syscall上阻塞的 M 的 P ; - 发信号,抢占已经执⾏时间过⻓的 G。
本文由 简悦 SimpRead 转码, 原文地址 alanhou.org
理解可执行文件 Go 进程的启动与初始化 调度组件与调度循环 处理阻塞 调度器的发展历史 与调度有关的常⻅问题 暖场内容 跨语⾔学习 PHP 转 Go PHP-FPM 是多进程模型,FPM 内单线程执⾏。
- 理解可执行文件
- Go 进程的启动与初始化
- 调度组件与调度循环
- 处理阻塞
- 调度器的发展历史
- 与调度有关的常⻅问题
暖场内容
跨语⾔学习
PHP 转 Go
- PHP-FPM 是多进程模型,FPM 内单线程执⾏。PHP 底层是 C 语⾔实现,整套系统难精通。⽐如我遇到过 PHP 底层的 bug,束⼿⽆策。
- Go 从⽤户代码⼀直到底层都是 Go(会有⼀些汇编),相对来说要从上层学到底层容易很多,不要有⼼理负担。
- Go 代码是强类型语⾔的写法,分层之间有清晰的结构体定义,⼤项⽬好维护。
Python 转 Go
- Python 转 Go 同样也是⼀个趋势,Python 底层是 C 实现,想把整套系统学精通有⼀定难度。
- 在线系统中 Go 的性能要⽐ Python 好很多。
- 因为强类型的写法,Go 代码要⽐ Python 好维护。
⼯程师的学习与进步
多写代码,积累代码量 (⾄少积累⼏⼗万的代码量,才能对设计有⾃⼰的观点),要总结和思考,如何对过去的⼯作进⾏改进 (如⾃动化 / 系统化);积累⾃⼰的代码库、笔记库、开源项⽬。
读好书,建⽴知识体系 (⽐如像 Designing Data-Intensive Application,中文 GitHub 版:设计数据密集型应用这种书,应该读好多遍)。
关注⼀些靠谱的国内外新闻源,通过问题出发,主动使⽤ Google,主动去 reddit、hackernews 上参与讨论,避免被困在信息茧房中。
锻炼**⼝才和演讲能⼒**,内部分享 -> 外部分享。在公司内,该演要演,不要只是闷头⼲活。
通过输出促进输⼊ (博客、公众号、分享),打造个⼈品牌,通过读者的反馈循环提升⾃⼰的认知。(费曼学习法)
信息源:Github Trending、Reddit、Medium、Hacker News,morning paper(作者不⼲了),acm.org,O’Reilly,国外的领域相关⼤会 (如 OSDI,SOSP,VLDB) 论⽂,国际⼀流公司的技术博客,YouTube 上的国外⼯程师演讲。
为什么 Go 语⾔适合现代的后端编程环境?
- 服务类应⽤以 API 居多,IO 密集型,且⽹络 IO 最多
- 运⾏成本低,⽆ VM。⽹络连接数不多的情况下内存占⽤低。
- 强类型语⾔,易上⼿,易维护。
为什么适合基础设施?
- k8s、etcd、istio、docker 已经证明了 Go 的能⼒
对 Go 的启动和执⾏流程建⽴简单的宏观认识
理解可执⾏⽂件
实验使用的 Dockerfile(鉴于 CentOS 8 已正式停止维护,可将 centos 镜像替换为 rockylinux)
FROM centos
RUN yum install golang -y \
&& yum install dlv -y \
&& yum install binutils -y \
&& yum install vim -y \
&& yum install gdb -y
构建镜像和启动容器进入的命令
docker build -t test .
docker run -it --rm test bash
vim tab 空格数的配置(~/.vimrc)
set ts=4
set softtabstop=4
set shiftwidth=4
set expandtab
set autoindent
Go 程序 hello.go 的编译过程:
可执行go build -x hello.go进行查看,代码中高亮的两行分别为 complie(编译)和 link(链接)部分:
# go build -x hello.go
WORK=/tmp/go-build2676931951
mkdir -p $WORK/b001/
cat >$WORK/b001/_gomod_.go << 'EOF' # internal
package main
import _ "unsafe"
//go:linkname __debug_modinfo__ runtime.modinfo
var __debug_modinfo__ = "0w\xaf\f\x92t\b\x02A\xe1\xc1\a\xe6\xd6\x18\xe6path\tcommand-line-arguments\nmod\tcommand-line-arguments\t(devel)\t\n\xf92C1\x86\x18 r\x00\x82B\x10A\x16\xd8\xf2"
EOF
cat >$WORK/b001/importcfg << 'EOF' # internal
# import config
packagefile runtime=/usr/lib/golang/pkg/linux_amd64/runtime.a
EOF
cd /cao/hello
/usr/lib/golang/pkg/tool/linux_amd64/compile -o $WORK/b001/_pkg_.a -trimpath "$WORK/b001=>" -p main -complete -buildid u9rA4S8cPkMjRUT56udb/u9rA4S8cPkMjRUT56udb -goversion go1.16.12 -D _/cao/hello -importcfg $WORK/b001/importcfg -pack -c=4 ./hello.go $WORK/b001/_gomod_.go
/usr/lib/golang/pkg/tool/linux_amd64/buildid -w $WORK/b001/_pkg_.a # internal
cp $WORK/b001/_pkg_.a /root/.cache/go-build/2b/2be70e10778e5b23d83770351d1a7908724204d8a6bcace8ecb1b31eb14d4eed-d # internal
cat >$WORK/b001/importcfg.link << 'EOF' # internal
packagefile command-line-arguments=$WORK/b001/_pkg_.a
packagefile runtime=/usr/lib/golang/pkg/linux_amd64/runtime.a
packagefile internal/bytealg=/usr/lib/golang/pkg/linux_amd64/internal/bytealg.a
packagefile internal/cpu=/usr/lib/golang/pkg/linux_amd64/internal/cpu.a
packagefile runtime/internal/atomic=/usr/lib/golang/pkg/linux_amd64/runtime/internal/atomic.a
packagefile runtime/internal/math=/usr/lib/golang/pkg/linux_amd64/runtime/internal/math.a
packagefile runtime/internal/sys=/usr/lib/golang/pkg/linux_amd64/runtime/internal/sys.a
EOF
mkdir -p $WORK/b001/exe/
cd .
/usr/lib/golang/pkg/tool/linux_amd64/link -o $WORK/b001/exe/a.out -importcfg $WORK/b001/importcfg.link -buildmode=exe -buildid=zsLvUjr6eNKNNK8GfKhl/u9rA4S8cPkMjRUT56udb/6IkzwXMvzyUSdMJzmjRJ/zsLvUjr6eNKNNK8GfKhl -extld=gcc $WORK/b001/_pkg_.a
/usr/lib/golang/pkg/tool/linux_amd64/buildid -w $WORK/b001/exe/a.out # internal
mv $WORK/b001/exe/a.out hello
rm -r $WORK/b001/
编译是将文本代码编译为目标文件 (.o, .a),链接是将目标文件合并为可执行文件。可执行文件在不同的操作系统上规范也不同:
| Linux | Windows | macOS |
|---|---|---|
| ELF | PE | Mach-O |
Linux 的可执⾏⽂件 ELF(Executable and Linkable Format) 为例,ELF 由⼏部分构成:
- ELF header
- Section header
- Sections
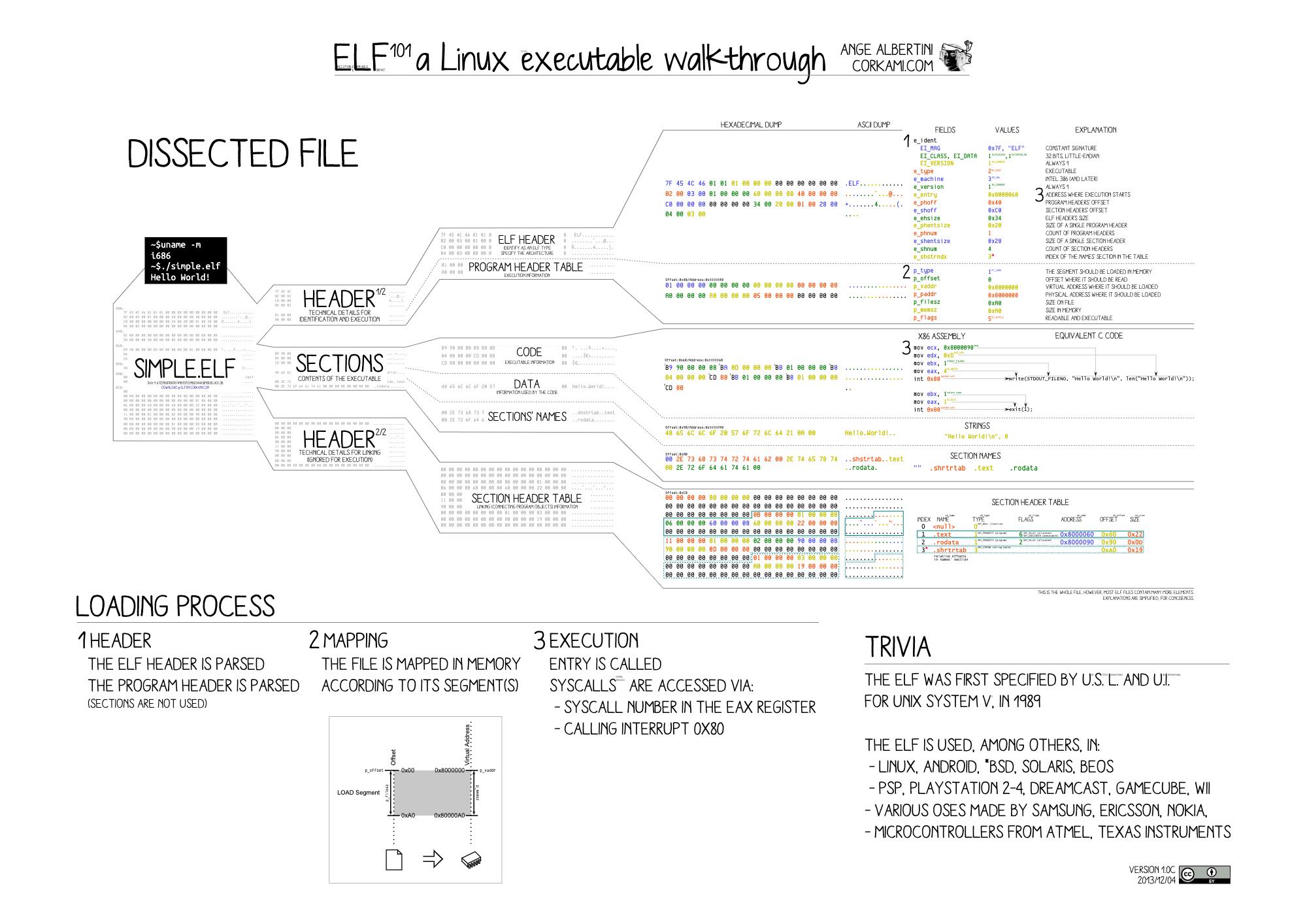 图片来源:https://github.com/corkami/pics/blob/28cb0226093ed57b348723bc473cea0162dad366/binary/elf101/elf101.pdf
图片来源:https://github.com/corkami/pics/blob/28cb0226093ed57b348723bc473cea0162dad366/binary/elf101/elf101.pdf
操作系统执⾏可执⾏⽂件的步骤 (以 linux 为例):

通过 entry point 找到 Go 进程的执⾏⼊⼝,使⽤ readelf(readelf -h ./hello)
# readelf -h ./hello
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x45cd80
Start of program headers: 64 (bytes into file)
Start of section headers: 456 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 7
Size of section headers: 64 (bytes)
Number of section headers: 23
Section header string table index: 3
通过以上的入口地址0x45cd80可借助dlv命令来设置断点找到代码位置(事实上进入后默认已经在入口位置):
# dlv exec ./hello
Type 'help' for list of commands.
(dlv) b *0x45cd80
Breakpoint 1 set at 0x45cd80 for _rt0_amd64_linux() /usr/lib/golang/src/runtime/rt0_linux_amd64.s:8
(dlv)
常用的命令: c, si, r, n, disass,更多参见 https://github.com/go-delve/delve
Running the program:
call ------------------------ Resumes process, injecting a function call (EXPERIMENTAL!!!)
continue (alias: c) --------- Run until breakpoint or program termination.
next (alias: n) ------------- Step over to next source line.
rebuild --------------------- Rebuild the target executable and restarts it. It does not work if the executable was not built by delve.
restart (alias: r) ---------- Restart process.
step (alias: s) ------------- Single step through program.
step-instruction (alias: si) Single step a single cpu instruction.
stepout (alias: so) --------- Step out of the current function.
Manipulating breakpoints:
break (alias: b) ------- Sets a breakpoint.
breakpoints (alias: bp) Print out info for active breakpoints.
clear ------------------ Deletes breakpoint.
clearall --------------- Deletes multiple breakpoints.
condition (alias: cond) Set breakpoint condition.
on --------------------- Executes a command when a breakpoint is hit.
trace (alias: t) ------- Set tracepoint.
Viewing program variables and memory:
args ----------------- Print function arguments.
display -------------- Print value of an expression every time the program stops.
examinemem (alias: x) Examine memory:
locals --------------- Print local variables.
print (alias: p) ----- Evaluate an expression.
regs ----------------- Print contents of CPU registers.
set ------------------ Changes the value of a variable.
vars ----------------- Print package variables.
whatis --------------- Prints type of an expression.
Listing and switching between threads and goroutines:
goroutine (alias: gr) -- Shows or changes current goroutine
goroutines (alias: grs) List program goroutines.
thread (alias: tr) ----- Switch to the specified thread.
threads ---------------- Print out info for every traced thread.
Viewing the call stack and selecting frames:
deferred --------- Executes command in the context of a deferred call.
down ------------- Move the current frame down.
frame ------------ Set the current frame, or execute command on a different frame.
stack (alias: bt) Print stack trace.
up --------------- Move the current frame up.
Other commands:
config --------------------- Changes configuration parameters.
disassemble (alias: disass) Disassembler.
edit (alias: ed) ----------- Open where you are in $DELVE_EDITOR or $EDITOR
exit (alias: quit | q) ----- Exit the debugger.
funcs ---------------------- Print list of functions.
help (alias: h) ------------ Prints the help message.
libraries ------------------ List loaded dynamic libraries
list (alias: ls | l) ------- Show source code.
source --------------------- Executes a file containing a list of delve commands
sources -------------------- Print list of source files.
types ---------------------- Print list of types
Go 进程的启动与初始化
有助于深入汇编的游戏:人力资源机器(Human Resource Machine)
CPU 无法理解文本,只能执行一条一条的二进制机器码指令 每次执行完一条指令,pc 寄存器就指向下一条继续执行
在 64 位平台上 pc 寄存器 = rip

Go 语⾔是⼀⻔有 runtime 的语⾔,runtime 是为了实现额外的功能,⽽在程序运⾏时⾃动加载 / 运⾏的⼀些模块。(下图仅供参考,不够严谨,线程创建在 Linux 中也是通过系统调用)
 Go 语⾔的 runtime 包括如下模块:
Go 语⾔的 runtime 包括如下模块:
| Scheduler | 调度器管理所有的 G,M,P,在后台执⾏调度循环 |
| Netpoll | ⽹络轮询负责管理⽹络 FD 相关的读写、就绪事件 |
| Memory Management | 当代码需要内存时,负责内存分配⼯作 |
| Garbage Collector | 当内存不再需要时,负责回收内存 |
这些模块中,最核⼼的就是 Scheduler,它负责串联所有的 runtime 流程。
通过 entry point 找到 Go 进程的执⾏⼊⼝,它会通过 3 个回调函数一路跳到 runtime.rt0_go 这个函数里,该函数是初始化的一个非常重要的函数。下图中 m0 为 Go 程序启动后创建的第⼀个线程,执行 main 函数后开始进入调试循环:
调度组件与调度循环
在写下go func(){...}的时候,其实是向 runtime 提交了⼀个计算任务。 func(){...}⾥包裹的代码,就是这个计算任务的内容。所以 Go 的调度流程本质上是⼀个⽣产 - 消费流程:
go func 去了哪⾥?
goroutine 的生产端
goroutine 的消费端
M 执行调度循环时, 必须与一个 P 绑定。Work stealing 就是说的 runqsteal -> runqgrab 这个流程。
每执行 60 次本地队列的获取(可参见下图中使用的是一个魔法数字 61),就会去全局队列中检查一次
下图中 P.schedtick 即为记录前面本地队列获取的次数
使用是 M:N 模型?关于 GMP 的说明:
- G:goroutine,⼀个计算任务。由需要执⾏的代码和其上下⽂组成,上下⽂包括:当前代码位置,栈顶、栈底地址,状态等。
- M:machine,系统线程,执⾏实体,想要在 CPU 上执⾏代码,必须有线程,与 C 语⾔中的线程相同,通过系统调⽤ clone 来创建。
- P:processor,虚拟处理器,M 必须获得 P 才能执⾏代码,否则必须陷⼊休眠 (后台监控线程除外),你也可以将其理解为⼀种 token,有这个 token,才有在物理 CPU 核⼼上执⾏的权⼒。
处理阻塞
在线程发生阻塞的时候, 会无限制地创建线程么?
并不会!! 先来看看阻塞有哪几种情况:
- make 了一个 buffer 是 0 的 channel,向里面塞数据:
// channel send
var ch = make(chan int)
ch <- 1
2.make 了一个 buffer 是 0 的 channel,去消费数据:
// channel recv
var ch = make(chan int)
<- ch
执行
time.sleep网络读,但无数据可读
// net read
var c net.Conn
var buf = make([]byte, 1024)
// data not ready, block here
n, err := c.Read(buf)
- 网络写,缓冲区已满
// net write
var c net.Conn
var buf = []byte("hello")
// send buffer full, write blocked
n, err := c.Write(buf)
- 执行 select,但 case 均为 ready
var (
ch1 = make(chan int)
ch2 = make(chan int)
)
// no case ready, block
select {
case <-ch1:
println("ch1 ready")
case <-ch2:
println("ch2 ready")
}
- 锁被其他人占用
var l sync.RWMutex
// somebody already grab the lock
// block here
l.Lock()
这些情况不会阻塞调度循环,而是会把 goroutine 挂起。所谓的挂起,其实让 g 先进某个数据结构,待 ready 后再继续执行,不会占用线程。这时候,线程会进入 schedule,继续消费队列,执行其它的 g
上述 6 种情况挂起的示意:
为何有的等待是 sudog,有的是 g 呢?
// sudog represents a g in a wait list, such as for sending/receiving
// on a channel.
//
// sudog is necessary because the g ↔ synchronization object relation
// is many-to-many. A g can be on many wait lists, so there may be
// many sudogs for one g; and many gs may be waiting on the same
// synchronization object, so there may be many sudogs for one object.
就是说一个 g 可能对应多个 sudog,比如一个 g 会同时 select 多个 channel。前面这些都是能被 runtime 拦截到的阻塞,还有一些是 runtime 无法拦截的:
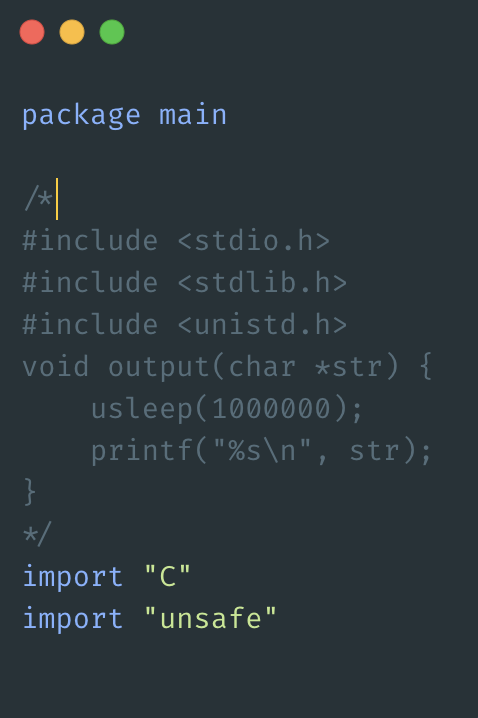
- cgo:在执行 c 代码,或者阻塞在 syscall 上时,必须占用一个线程
package main
/*
#include
#include
#include
void output(char *str) {
usleep(1000000);
printf("%s\n", str);
}
*/
import "C"
import "unsafe"
- syscall
sysnb: syscall nonblocking sys: syscall blocking
处理是通过 sysmon(system monitor),具有高优先级,在专有线程中执行,不需要绑定 P 就可以执行。主要有 3 个工作
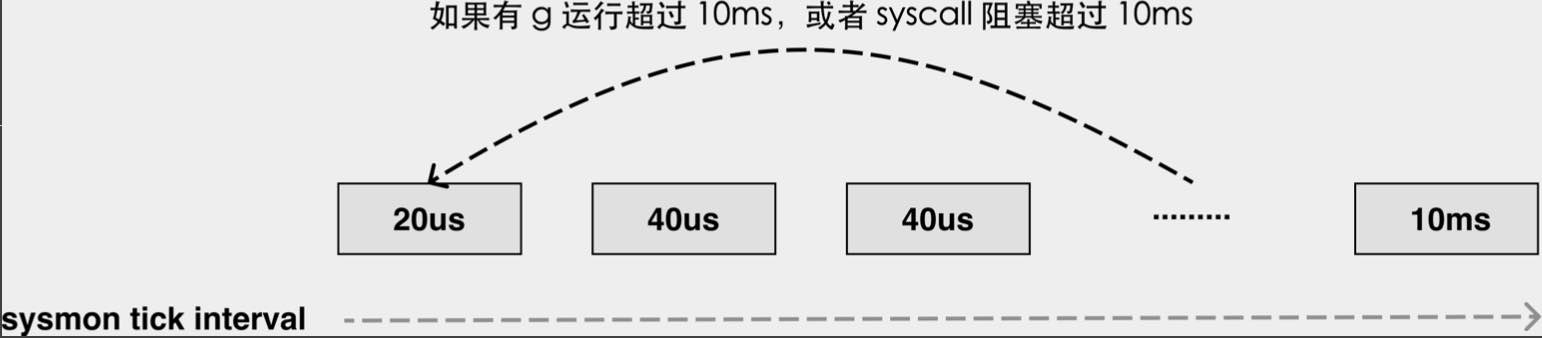
checkdead,常⻅误解是这个可以检查死锁
// Check for deadlock situation. // The check is based on number of running M's, if 0 -> deadlock.netpoll:
inject g list to global run queueretake
- 如果是 syscall 卡了很久,那就把 p 剥离 (handoffp)
- 如果是用户 g 运行很久了,那么发信号 SIGURG 抢占(Go 1.14 新增)
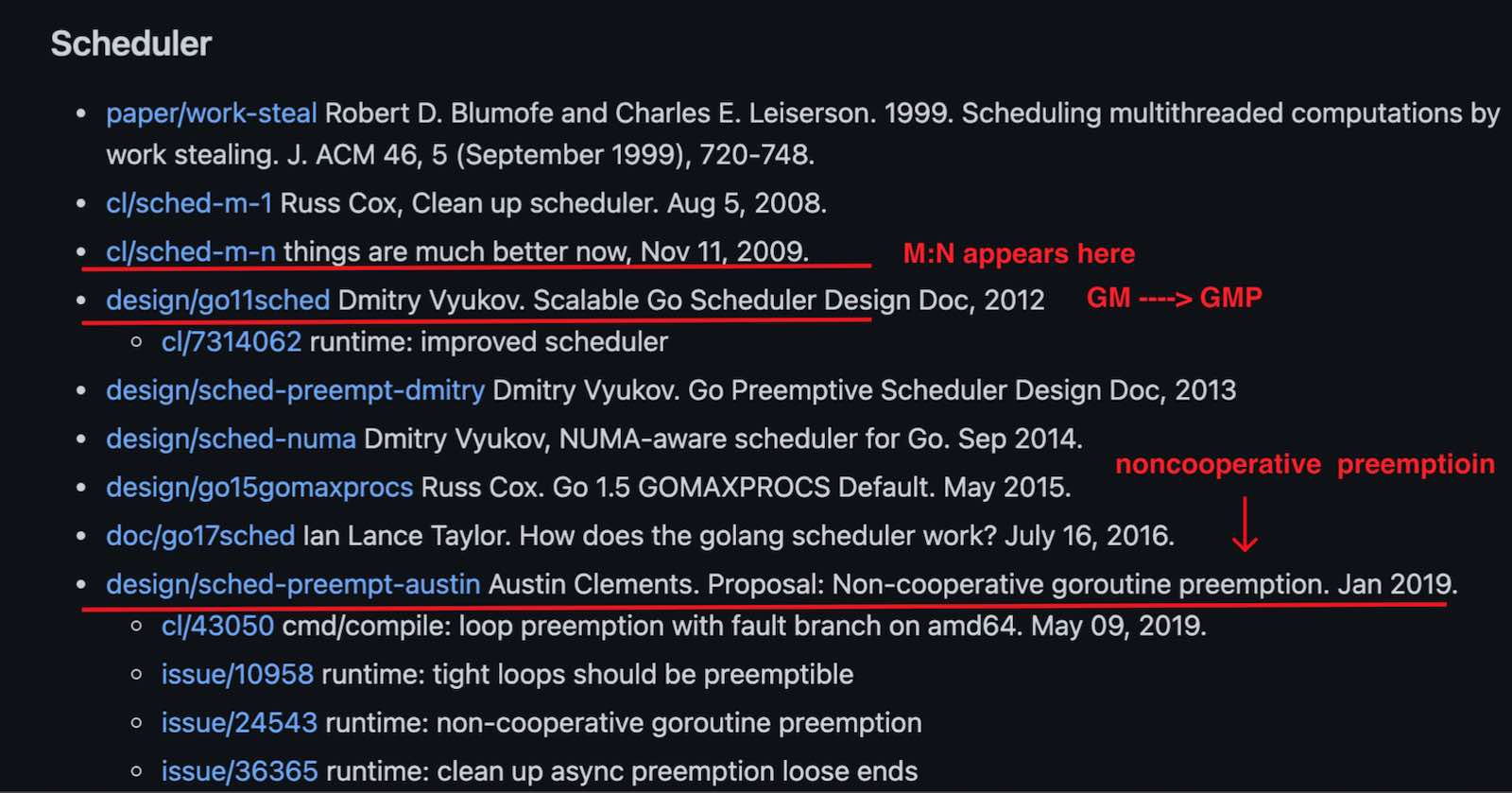
调度器的发展历史
参见:https://github.com/golang-design/history#scheduler
小结
可执行文件 ELF:
- 使用 go build -x 观察编译和链接过程
- 通过 readelf -H 中的 entry 找到程序入口
- 在 dlv 调试器中 b *entry_addr 找到代码位置
启动流程:
- 处理参数 -> 初始化内部数据结构 -> 主线程 -> 启动调度循环
Runtime 构成:
- Scheduler、Netpoll、内存管理、垃圾回收
GMP:
- M,任务消费者; G,计算任务; P,可以使用 CPU 的 token
队列:
- P 的本地 runnext 字段 -> P 的 local run queue -> global run queue,多级队列减少锁竞争
调度循环:
- 线程 M 在持有 P 的情况下不断消费运行队列中的 G 的过程。
处理阻塞:
- 可以接管的阻塞: channel 收发,加锁,网络连接读 / 写,select
- 不可接管的阻塞: syscall,cgo,⻓时间运行需要剥离 P 执行
sysmon:
- 一个后台高优先级循环,执行时不需要绑定任何的 P
- 负责:
- 检查是否已经没有活动线程,如果是,则崩溃 轮询 netpoll
- 剥离在 syscall 上阻塞的 M 的 P 发信号,抢占已经执行时间过⻓的 G
补充:与调度有关的常⻅问题
Goroutine 比 Thread 优势在哪?
| Goroutine | Thread | |
|---|---|---|
| 内存占用 | 2KB -> 1GB | 从 8k 开始,服务端程序上限很多是 8M(用 ulimit -a 可看),调用多会 stack overflow |
| Context switch | 几十 NS 级 | 1-2 us |
| 由谁管理 | Go runtime | 操作系统 |
| 通信方式 | CSP / 传统共享内存 | 传统共享内存 |
| ID | 有,用户无法访问 | 有 |
| 抢占 | 1.13 以前需主动让出 1.14 开始可由信号中断 | 内核抢占 |
参考链接:https://www.geeksforgeeks.org/golang-goroutine-vs-thread/
goroutine 的切换成本
gobuf 描述一个 goroutine 所有现场,从一个 g 切换到另一个 g,只要把这几个现场字段保存下来,再把 g 往队列里一扔,m 就可以执行其它 g 了。无需进入内核态
一个无聊的输出顺序的问题
第一段代码:
package main
import (
"fmt"
"runtime"
)
func main() {
runtime.GOMAXPROCS(1)
for i := 0; i < 10; i++ {
i := i
go func() {
fmt.Println("A:", i)
}()
}
var ch = make(chan int)
<-ch
}
第二段代码:
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
runtime.GOMAXPROCS(1)
for i := 0; i < 10; i++ {
i := i
go func() {
fmt.Println("A:", i)
}()
}
time.Sleep(time.Hour)
}
死循环导致进程 hang 死问题
GC 时需要停止所有 goroutine 而老版本的 Go 的 g 停止需要主动让出
1.14 增加基于信号的抢占之后,该问题被解决
package main
func main() {
var i = 1
go func() {
// 这个 goroutine 会导致进行在 gc 时 hang 死
for {
i++
}
}()
}
链接:https://xargin.com/how-to-locate-for-block-in-golang/
与 GMP 有关的一些缺陷
- 创建的 M 正常情况下是无法被回收
解决方法:https://xargin.com/shrink-go-threads/ - runtime 中有一个 allgs 数组 所有创建过的 g 都会进该数组 大小与 g 瞬时最高值相关
详细说明:https://xargin.com/cpu-idle-cannot-recover-after-peak-load/
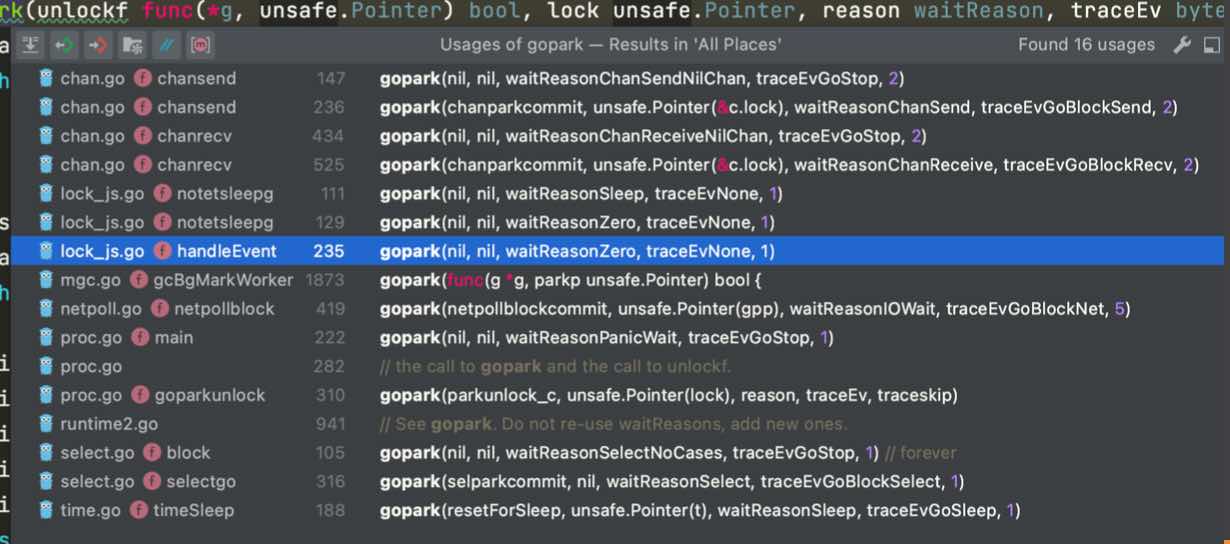
在 PPT 里有各种阻塞场景,你是怎么在代码里找到这些阻塞场景的?
要知道 runtime 中可以接管的阻塞是通过 gopark/goparkunlock 挂起和 goready 恢复 的,那么我们只要找到 runtime.gopark 的调用方,就可以知道在哪些地方会被 runtime 接管了,你也应该用 IDE 试一试,很简单:
其它参考链接:
Measuring context switching and memory overheads for Linux threads
课后作业
- 部署好本机的 docker 环境,使用 ppt 中的 dockerfile build 自己的环境
- 使用 readelf 工具,查看编译后的进程入口地址
readelf -h ./hello | grep Entry - 在 dlv 调试工具中,使用断点功能找到代码位置
- 使用断点调试功能,查看 Go 的 runtime 的下列函数执行流程,使用 IDE 查看函数的调用方:
- 必做:runqput,runqget,globrunqput,globrunqget
➤ dlv 进入后,输入b runqput,然后输入c或continue,如执行完成可输入r或restart重新开启执行
➤ Goland 中使用 Cmd+Opt+o 搜索runqput函数,按下 Cmd,单击函数名 - 选做:schedule,findrunnable,sysmon
- 必做:runqput,runqget,globrunqput,globrunqget
- 难度 ++ 课外作业:跟踪进程启动流程中的关键函数,rt0_go,需要汇编知识,可以暂时不做,只给有兴趣的同学
内容来源为曹大的《Go 高级工程师实战营》,想要报名的小伙伴请访问 https://learn.gocn.vip/course(无偿广告,内容是否适合读者请自行评估)。